Что помогает стартапам использовать методы глубинного обучения в своих проектах?
Трансферное обучение: почему deep learning стал доступнее

Раньше глубинное обучение требовало огромных мощностей, денежных инвестиций и времени, поэтому было недоступно небольшим компаниям. В последние годы ситуация меняется: стартапы и даже энтузиасты-одиночки могут использовать методы глубинного обучения в своих проектах. Разработчик Калеб Кайзер делится своими наблюдениями о том, почему deep learning становится все доступнее.
Раньше для того, чтобы заняться глубинным обучением, вы должны были иметь доступ к большому очищенному набору данных и самостоятельно разработать и обучить эффективную модель. Значит, проекты без существенной поддержки извне были невозможны по умолчанию. Однако за последние пару лет всё изменилось. Движущая сила такого роста — трансферное обучение.
Что такое трансферное обучение?
Идея трансферного обучения строится на том, что знания, накопленные в модели, подготовленной для выполнения одной задачи — скажем, распознавания цветов на фотографии — могут быть перенесены на другую модель, чтобы помочь в построении прогнозов для другой, родственной задачи, например, для задачи выявления меланомы.
Существуют различные подходы к трансферному обучению, но один из них — тонкая настройка (finetuning) — находит особенно широкое применение.
При таком подходе команда берет предварительно обученную модель и удаляет или переучивает последние слои этой модели, чтобы сфокусироваться на новой, схожей задаче. Например, AI Dungeon — это текстовая приключенческая игра с открытым миром, которая стала очень популярной из-за того, насколько убедительны сюжеты, написанные с помощью искусственного интеллекта:
Примечательно, что AI Dungeon не была разработана исследовательской лабораторий Google, это проект одного человека, сделанный во время хакатона.
Ник Уолтон, создатель AI Dungeon, не построил ее с нуля, а с помощью новейшей NLP-модели — GPT-2 компании OpenAI — доработал ее тонкой настройкой и дал возможность писать свои тексты для приключений.
Причина, по которой это вообще работает, в том, что в нейросетях базовые слои фокусируются на простых, общих паттернах, тогда как последние слои фокусируются на более специфичных паттернах для задач классификации или регрессии. Профессор Стенфордского университета Эндрю Ын визуализирует слои и их относительные уровни специфичности, представляя модель распознавания образов:
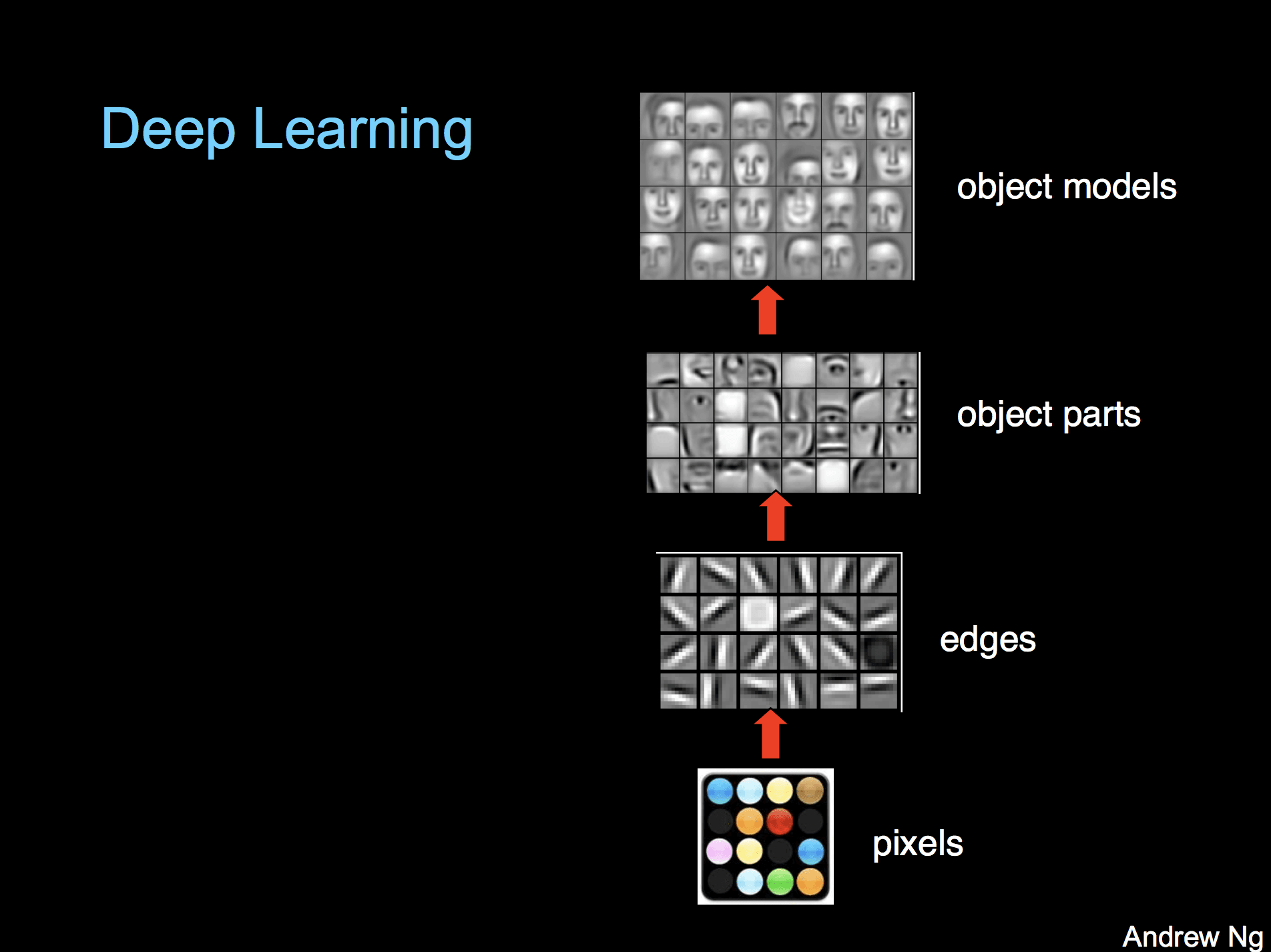
Общее содержание базовых слоев, оказывается, часто хорошо перекладывается на другие задачи. Например, в случае AI Dungeon GPT-2 обладала современным пониманием разговорного английского языка, ей просто потребовалась небольшая перетренировка в заключительных слоях для хороших результатов в создании собственных приключенческих сюжетов.
С помощью этого процесса один разработчик может развернуть модель, которая за несколько дней достигнет современных уровней развития в новой области.
Небольшие наборы данных больше не помеха
Глубинное обучение, как правило, требует больших объемов размеченных данных, а во многих областях таких данных просто не существует. Трансферное обучение может решить эту проблему. Например, команда, связанная с Гарвардской медицинской школой, недавно развернула модель, которая может на основе рентгенограмм грудной клетки прогнозировать смертность в долгосрочной перспективе, в том числе не связанную с раком.
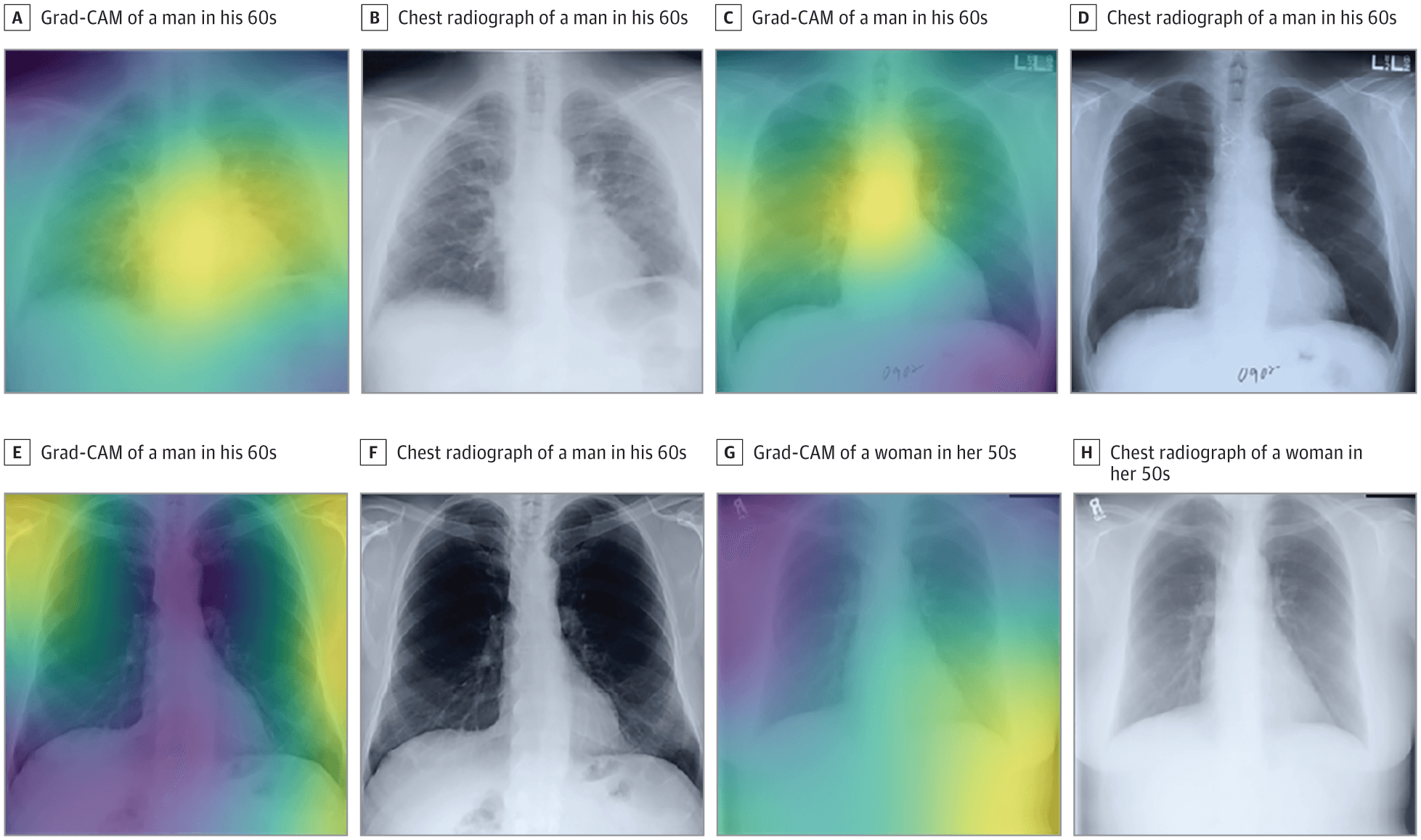
Несмотря на то, что у исследователей был набор данных, состоявший примерно из 50 000 размеченных изображений, они не могли тренировать собственную свёрточную нейросеть с нуля. Вместо этого они взяли подготовленную модель Inception-v4 (которая обучается на наборе данных, состоящем более чем из 14 миллионов изображений ImageNet) и использовали трансферное обучение и небольшие архитектурные модификации для адаптации модели к своему набору данных.
В результате их нейросеть научилась рассчитывать уровень риска по одному изображению грудной клетки пациента.
На обучение моделей теперь требуются минуты, а не дни
Обучение модели на огромном объеме данных требует не только приобретения этих данных, нужны также ресурсы и время.
Например, когда в Google разрабатывали свою state of the art модель классификации изображений Xception, были подготовлены две версии: одна на датасете ImageNet (14 миллионов изображений), а другая на наборе данных JFT (350 миллионов изображений).
Обучение на 60 графических процессорах NVIDIA K80 с различными оптимизациями заняло три дня для проведения одного эксперимента с ImageNet. Эксперимент с JFT занял больше месяца. Однако теперь, когда предварительно обученная модель Xception выпущена, команды могут провести тонкую настройку своих версий намного быстрее.
Например, команда из Университета штата Иллинойс и Аргоннской национальной лаборатории недавно подготовила модель для классификации изображений галактик.

Несмотря на то, что их набор данных составляет всего 35 000 размеченных изображений, они смогли настроить Xception всего за восемь минут с помощью графических процессоров NVIDIA.
Полученная модель способна классифицировать галактики с точностью 99,8% при сверхчеловеческой скорости.
Машинное обучение становится экосистемой
В программировании мы видим, как экосистемы «взрослеют» по довольно стандартным шаблонам. Появляется новый язык программирования с интересными возможностями, и его используют для определенных сценариев, исследовательских проектов и игр. Сегодня каждый, кто будет им пользоваться, должен собирать вспомогательные программы с нуля.
В итоге сообщество разрабатывает библиотеки и проекты, которые абстрагируются от общих утилит до тех пор, пока инструментарий не будет достаточно устойчив и работоспособен для использования. На этом этапе разработчики не думают об отправке HTTP-запросов или о подключении к базам данных, а сосредоточены исключительно на создании своего продукта.
Другими словами, большие компании создают свои модели, а разработчики используют их для создания продуктов. По мере того, как компании вроде OpenAI, Google, Facebook и других технологических гигантов выпускают мощные модели с открытым исходным кодом, инструменты в распоряжении разработчиков машинного обучения становятся все более мощными и стабильными.
Вместо того чтобы тратить время на построение модели с нуля при помощи PyTorch или TensorFlow, датасаентисты используют модели с открытым исходным кодом и трансферное обучение для создания продуктов, а значит, придет новое поколение программного обеспечения на основе программного обучения.
Теперь разработчикам машинного обучения остается думать только о том, как бы запустить эти модели в производство.