Объясняем механизм распознавания речи без интернета.
Как Алиса узнаёт, когда ей нужно включаться?

Большинство из вас хорошо знакомы с Алисой: голосовой помощник доступен в приложениях Яндекса и в различных умных устройствах. Команда Алисы постоянно пополняется стажёрами и участниками академических программ — ключевой проект компании делают молодые ребята. В том числе Алексей Рак. Лёша живёт в Минске и работает над голосовой активацией. Это механизм распознавания речи без интернета, что накладывает сложности на разработку.
Алисе нужен интернет, чтобы понимать речь. Ваше устройство записывает голос с помощью микрофона, немного сжимает запись и отправляет её на серверы: распознавание — сложная вычислительная задача, для выполнения которой требуются большие мощности. Но это если говорить о распознавании всей речи — всего алфавита и любых наборов слов. Разобрать несколько звуков гораздо проще, так что помощник умеет быстро «просыпаться», когда вы произносите слово «Алиса». Всё благодаря локальной детекции этого имени — она происходит без использования интернета, без обмена данными с серверами. Мы называем такое срабатывание голосовой активацией.
Лёша окончил Школу анализа данных и устроился в Яндекс в прошлом году — сначала был стажёром, а по окончании стажировки сохранил место в своей команде. На протяжении всей работы в компании он занимался именно голосовой активацией. В том числе он учит Алису откликаться только на её имя. Другой его задачей было продолжить процесс, начатый другими участниками команды: перенести новый алгоритм распознавания на всю линейку устройств. Этот новый алгоритм сделан более гибким по сравнению с предыдущим и готовым к дальнейшим улучшениям.
Чтобы о нём рассказать, сначала разберёмся, как телефоны, часы и колонки воспринимают нашу речь.
Как умные устройства нас «слышат»
Микрофон девайса преобразовывает речь в поток данных, который передаётся Алисе. Этот поток разбивается на короткие по времени фрагменты («фреймы»), они считываются с частотой в одну сотую секунды.
Вот как может выглядеть спектр звукового сигнала в одном фрейме:
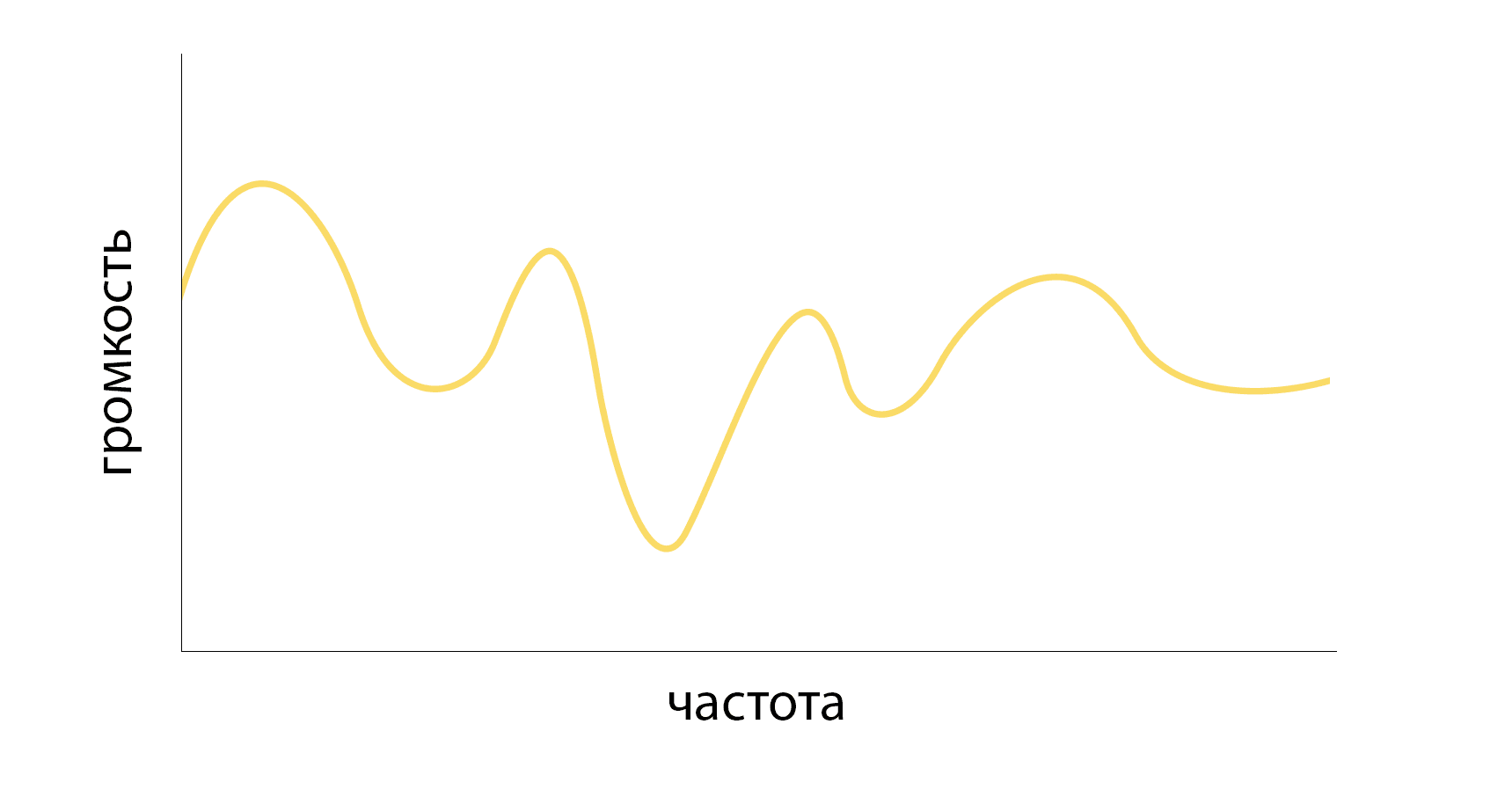
Этот график содержит множество данных — и о вашем голосе (мужской он или женский, высокий или низкий), и о произносимом звуке. Алисе неважно, кто назвал её имя, так что она должна проигнорировать данные о голосе, не учитывать их в алгоритме. Фрейм пропускается через фильтр, а затем, чтобы оставить только информацию о звуке, с ним выполняется ещё несколько математических преобразований и упрощений. Они основаны на опыте специалистов по речевым технологиям со всего мира. График может стать таким:
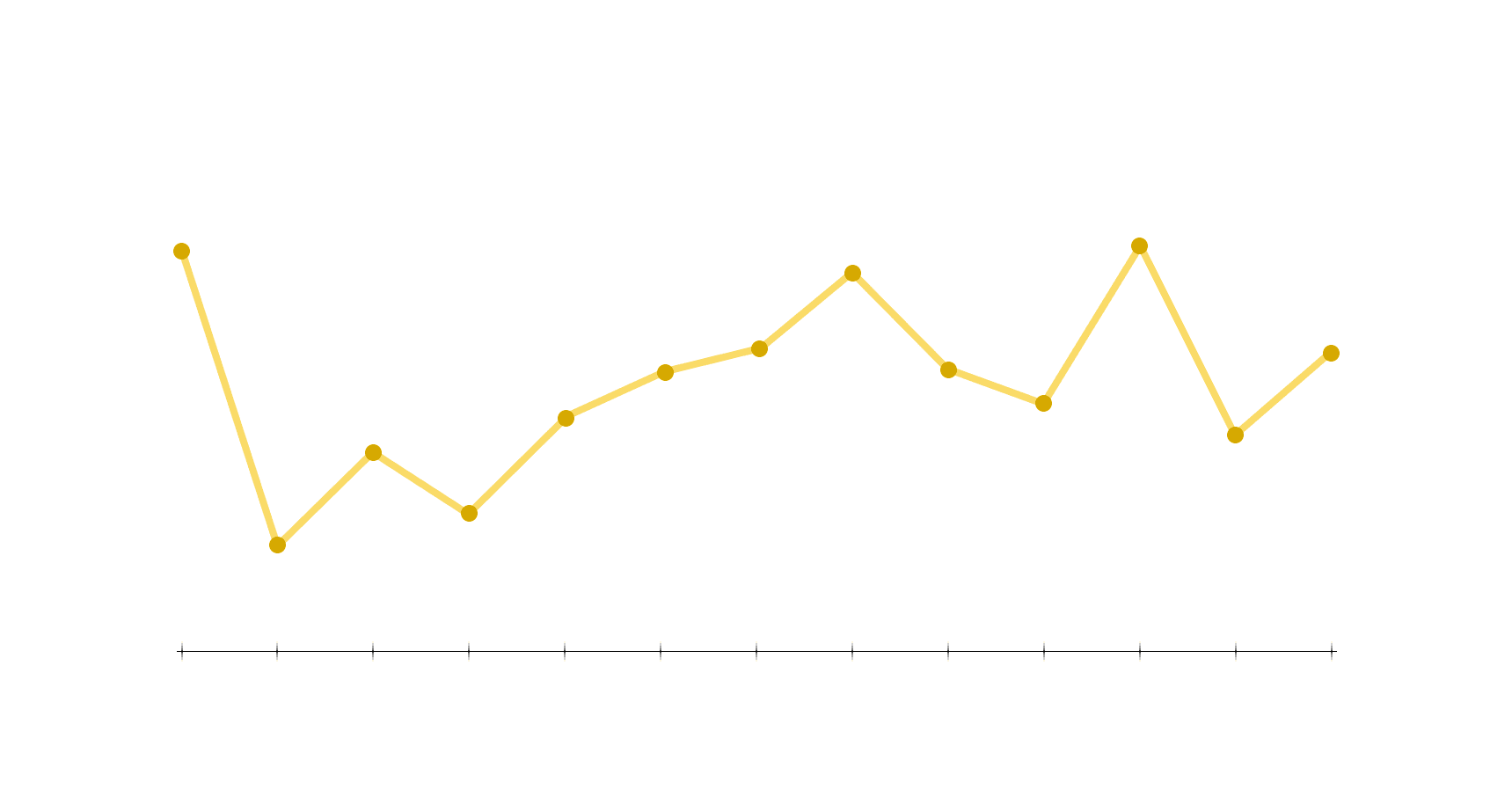
Получается, что его вид будет таким вне зависимости от пола или возраста говорящего.
Запишем высоту графика в отмеченных точках. Здесь 13 точек, получится 13 чисел, как и в реальной модели. Но можно выбрать и другое количество точек — это тоже делается исходя из опыта и специфики дальнейших преобразований.
Сколько мы тратим на звук [а]
Мы разобрались, как короткая запись речи с микрофона, фрейм длиной в сотые доли секунды, преобразуется в набор чисел. Напомним цель — «услышать» в голосе человека пять звуков, которые встречаются в слове «Алиса». Но чтобы произнести любой из этих звуков, человеку нужно больше времени, чем длится фрейм: не сотые, а десятые доли секунды. Так что из записи с микрофона берутся целые потоки фреймов, и уже по ним алгоритм старается понять, какой звук был произнесён.
Можно взять десятки фреймов и описанным выше способом представить каждый из них в виде набора чисел (в нашем примере набор содержит 13 чисел). Получатся десятки наборов:
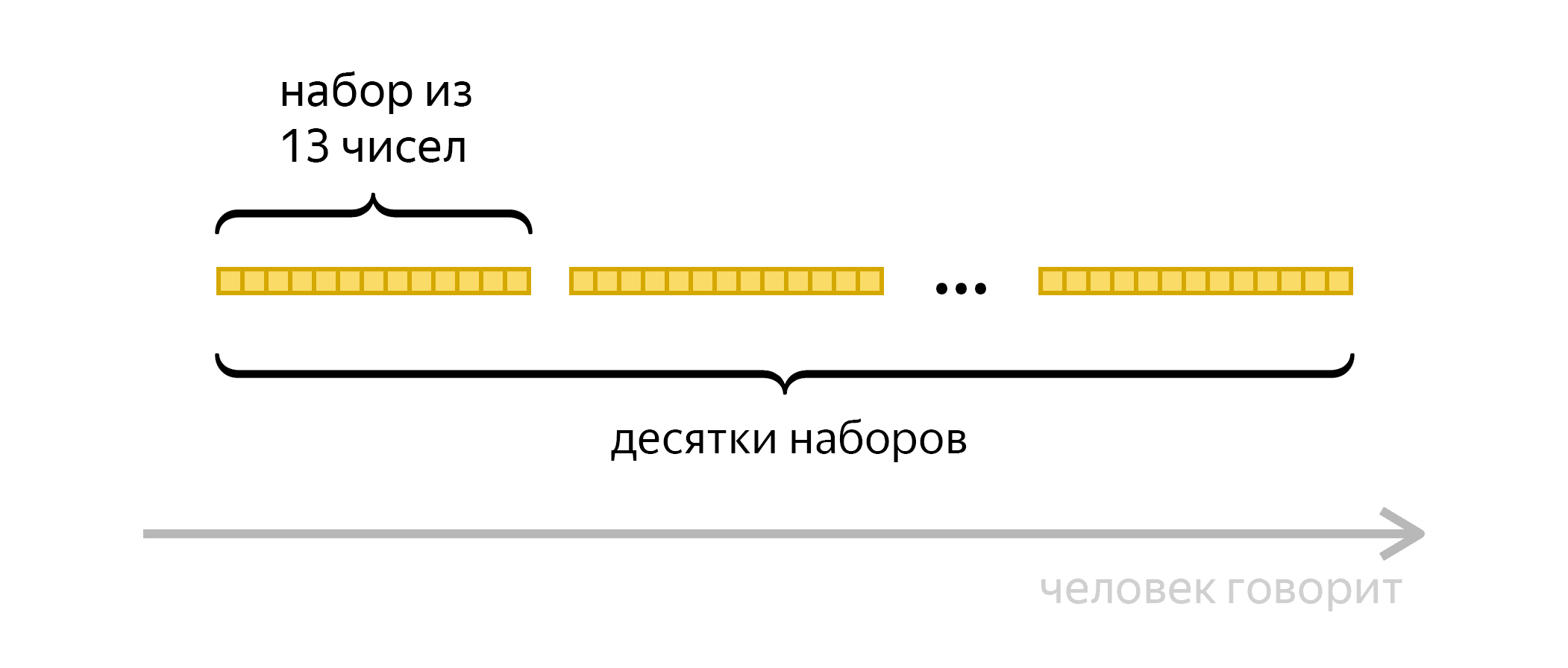
Чтобы распознать звук, закодированный в этих наборах, последовательность необходимо сжать при помощи нейронной сети:
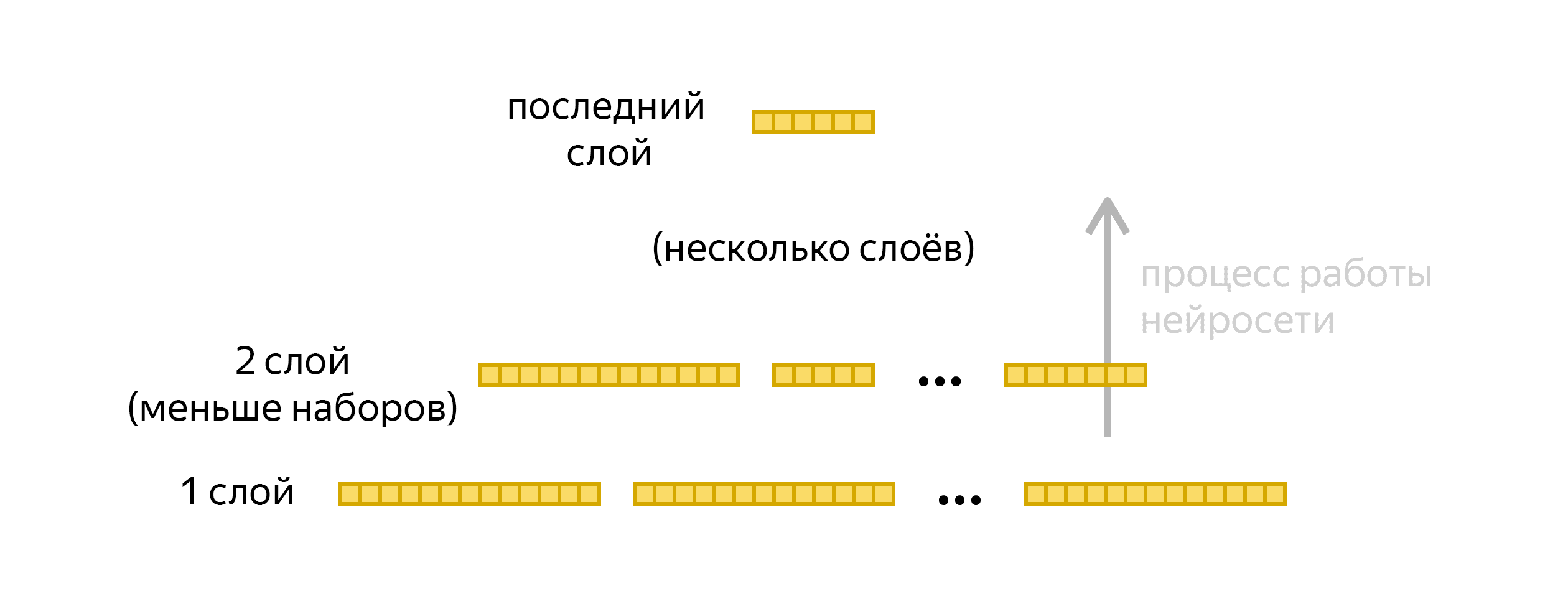
Как улучшить нейросеть
Каждый следующий слой сети — результат математических операций с наборами предыдущего слоя. В определённый момент числа из наборов перемножаются. Умножение — более ресурсоёмкая операция, чем, например, сложение. Понятно, что решить задачу вида «2 x 2 = ?» несложно ни для человека, ни для простейшего калькулятора. Но когда каждую секунду нужно перемножать тысячи чисел, справится не всякий процессор. Напомним, что мы не хотим отправлять данные для обработки на мощные серверы через интернет: сотовая сеть доступна не всегда, скорость часто оставляет желать лучшего, а устройство с Алисой должно реагировать на голос одинаково быстро, вне зависимости от каких-либо факторов. Важно, чтобы процессор самого девайса (возможно, недорогого смартфона) справился с алгоритмом и не потратил на обработку слишком много ресурсов. Иначе аккумулятор устройства быстро разрядится. Вывод: лучше снизить количество умножений чисел в нейронной сети.
Модель, которая раньше применялась в Алисе, работала хорошо. Однако она была более ресурсозатратной по сравнению с новой версией, которую Алексей сейчас адаптирует под разные девайсы. Идея улучшения в том, чтобы нейросеть использовала результаты умножения одних и тех же фреймов при обработке нескольких фрагментов речи:
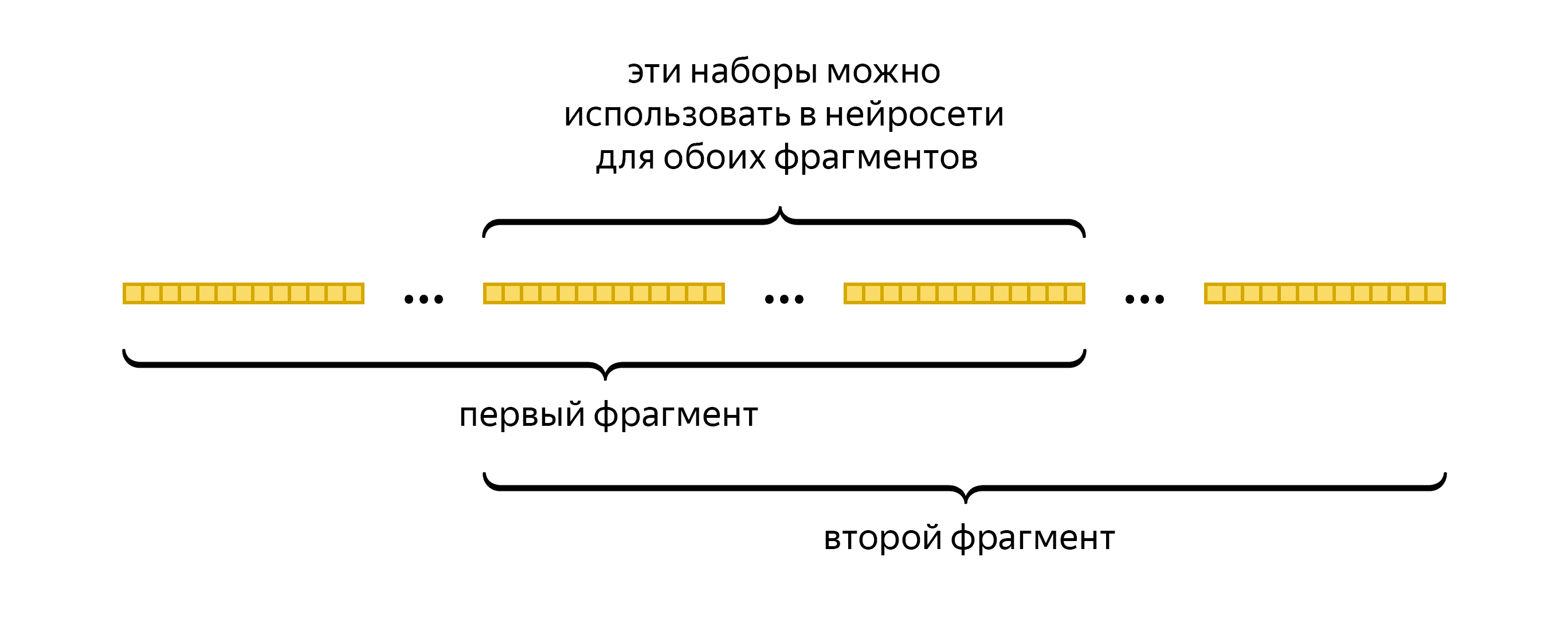
Раньше умножения для каждого фрагмента производились независимо, их общее число было больше. Теперь оно снизилось. Такая схема потребовала изменений в методе формирования слоёв нейросети, однако каждый следующий слой по-прежнему является результатом математических операций с предыдущим слоем.
— Нейроны и слои
Нейронные сети в IT — это программы, первые создатели которых вдохновлялись строением органических нейросетей. В спинном и головном мозге людей и животных нейроны расположены слоями и обмениваются импульсами. Точно так же и компьютерная модель передаёт числовые данные с одного слоя на другой, попутно применяя к ним математические операции. Цель — подготовить данные для дальнейшей обработки. Нейронами, в свою очередь, называют наборы данных. Система понятий, взятая из анатомии, просто определяет порядок работы алгоритма.
Алиса в числах
Нейронная сеть получает на вход десятки наборов чисел — а в качестве ответа возвращает только один набор:
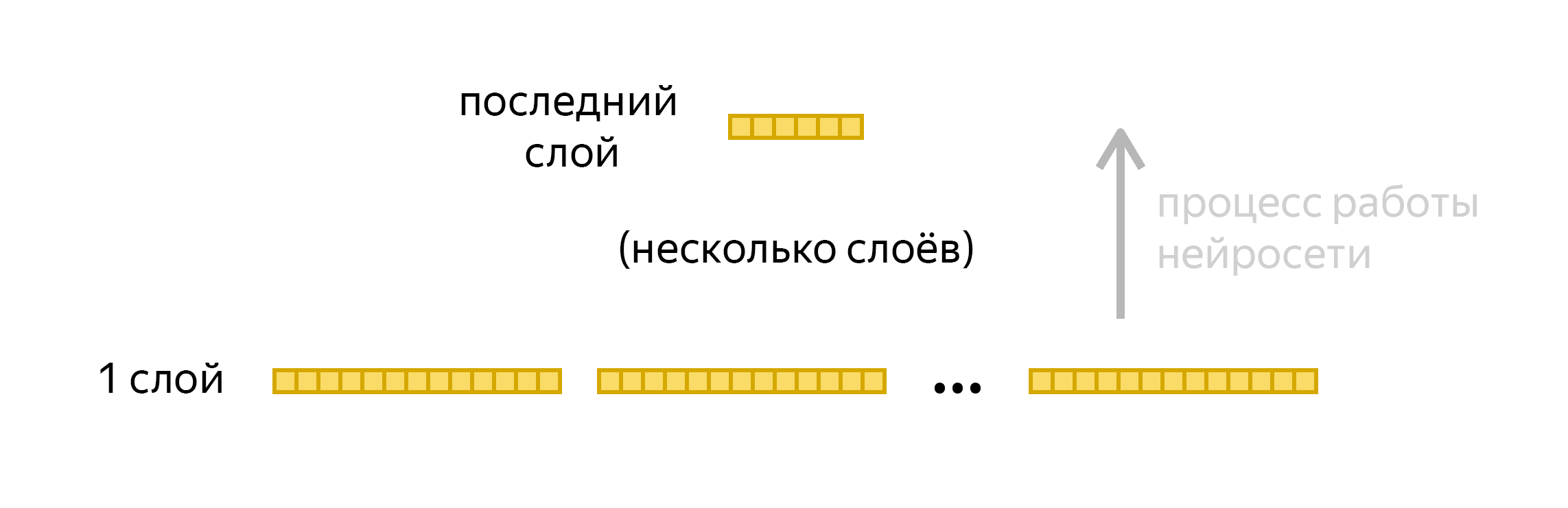
Он машиночитаемый, его несложно проинтерпретировать, а ещё он полностью характеризует тот звук, который человек произнёс за данный фрагмент времени. Если это [а], Алиса последовательно анализирует следующие фрагменты речи на наличие звуков [л’], [и] и так далее — пока не услышит своё имя целиком. Как только вы его произнесёте — помощник активируется.
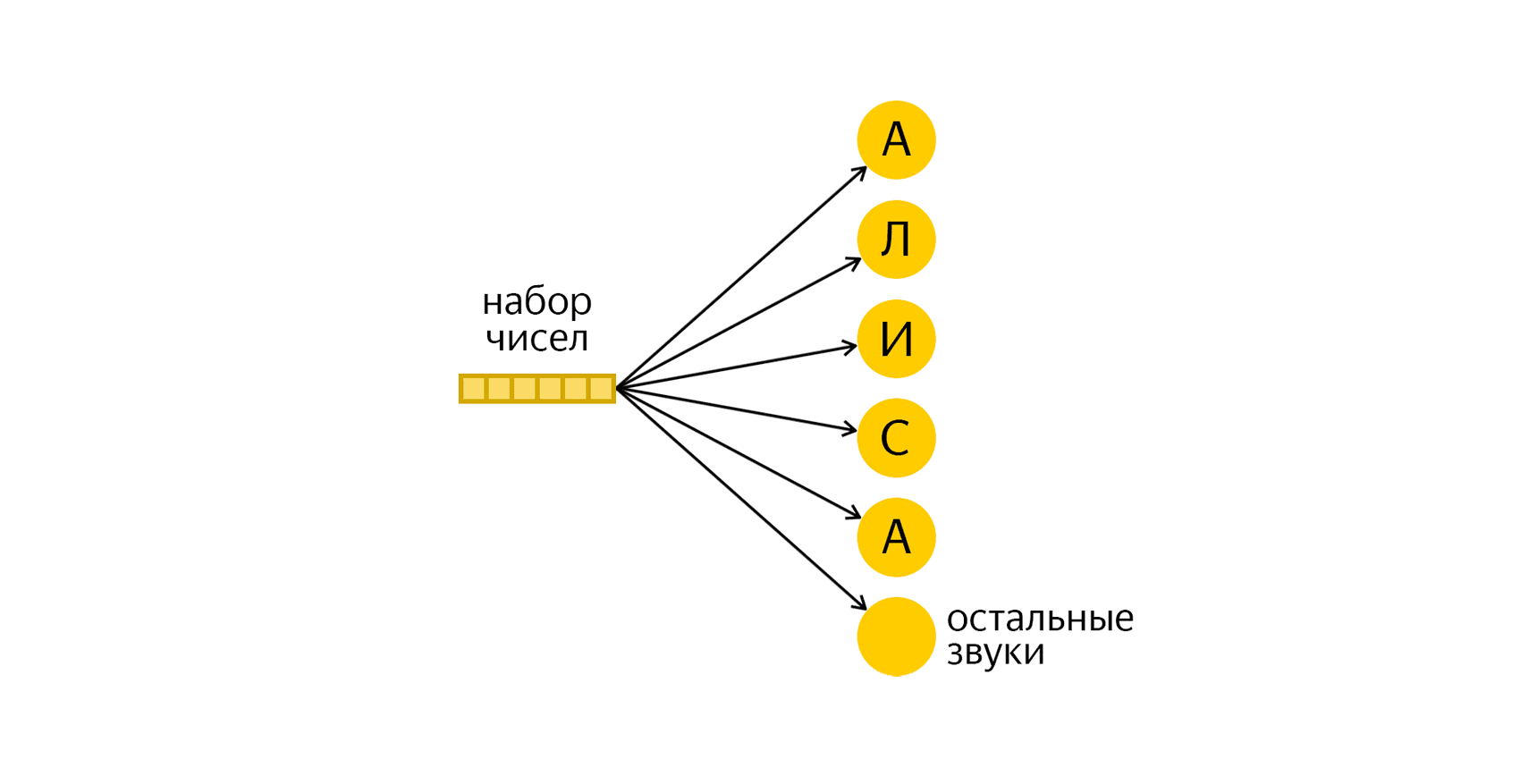
Количество чисел в наборе зависит от распознаваемых звуков.
Идея, которую Лёша использует, не нова, но было важно её правильно применить. Полученная нейросеть построена более оптимально и даёт больше возможностей для улучшений с точки зрения производительности (потребления ресурсов процессора). Она позволяет улучшить качество голосовой активации по слову «Алиса»: например, в Яндекс.Навигаторе доля ложных срабатываний уменьшилась в семь раз. При этом скорость реакции помощника не страдает даже на слабых устройствах.