«Холодные» пользователи и многорукие бандиты.
Как устроены рекомендации в Яндекс.Музыке

Одна из ключевых функций Яндекс.Музыки — предлагать пользователям треки, которые они пока не слышали, но могут оценить. Предпочтения можно узнать несколькими способами: от анализа прошлых прослушиваний до сравнения спектрограмм песен. Руководитель группы рекомендательных продуктов Медиасервисов Яндекса Даниил Бурлаков и разработчик Илья Игашов рассказали, каким образом сервис советует новый или редкий контент, у которого пока нет статистики прослушиваний, и что общего у игры в казино и рекомендательных алгоритмов.
Где даются рекомендации
Рекомендации используются в Яндекс.Радио (для подбора треков и ранжирования радиостанций) и в умных плейлистах Яндекс.Музыки. Например, в «Плейлисте дня». Он задумывался как набор треков, который каждый день строится так, чтобы перемешивать часто прослушиваемые записи с новыми — которые могут понравиться пользователю.

У рекомендательной системы Музыки две основные проблемы: это пользователи, которые только пришли на сервис, и поэтому про них еще ничего не известно, и «холодный» контент — редкие или недавно появившиеся треки, которые мало кто слушал.
Эти проблемы усугубились, когда Яндекс.Музыка стала международным сервисом. Так, при выходе в новые страны важно учитывать локальный контент и рекомендовать его. Но в России редко слушают, например, израильскую музыку, и статистики по ней не хватает.
Как работать с пользователями
Для того, чтобы рекомендовать треки новым пользователям, Яндекс.Музыка при регистрации просит их выбрать любимые жанры и музыкантов. Затем приложение подстраивает выдачу под то, какие записи человек слушает и как он их оценивает: для этого в Музыке можно ставить лайки и дизлайки.
«Пока про пользователя не набралось достаточно данных, рекомендации даются методом проб и ошибок», — говорит разработчик Яндекс.Музыки Илья Игашов. Например, в дашборде (рекомендациях) Радио всем новым пользователям долгое время показывали одинаковые радиостанции — самые популярные среди слушателей. В рамках своей бакалаврской работы на кафедре анализа данных МФТИ разработчик Илья Игашов попробовал применить алгоритм «многоруких бандитов»

Название метода отсылает нас к «одноруким бандитам» — игровым автоматам в казино. У «бандитов» есть рычаг, за который можно потянуть и получить выигрыш. Представьте, что вы находитесь в зале с такими автоматами и у вас есть некоторое количество бесплатных попыток для игры, однако вы не знаете, какой из автоматов может дать наибольшую прибыль. Задача игрока с «многоруким бандитом» в том, чтобы максимизировать средний выигрыш: найти самый выгодный автомат как можно быстрее и как можно меньше взаимодействовать с невыгодными.
Это довольно популярный алгоритм, особенно в задачах, связанных с показами чего-нибудь пользователям. Например, Netflix использует его для персонализации обложек фильмов и сериалов. Данные для обучения «бандитов» генерируются с помощью контролируемой случайной выдачи: наугад выбранные обложки показывают зрителям, и система записывает их поведение. У таких исследований есть своя цена: (пользователи временно получают не лучший опыт из возможных), но потери от него небольшие. При этом Netflix получает обратную связь по обложкам большой части каталога.
В Радио Яндекс.Музыки «многорукие бандиты» используются так: рекомендуемые станции — это ручки, а клики пользователей — выигрыш в автомате. Задача алгоритма будет в том, чтобы как можно быстрее понять, что та или иная станция «горячая», и начать её показывать.
Как работать с «холодным» контентом
«В случае холодного контента неприменимо решение „не рекомендовать“: в отличие от пользователей, он сам себя не „нагреет“», — говорит Даниил Бурлаков. Если разработчики не наберут статистику и не поднимут редкие треки в выдаче, то пользователи не смогут узнать о новинках любимых исполнителей. Аналогичная ситуация и с рекомендациями для жителей других стран: перед выходом Яндекс.Музыки на новые рынки у локальной музыки нет подходящего фидбека.
При этом редкий контент нельзя рекомендовать случайным образом, мало кто обрадуется, если у него в плейлисте просто так появится немецкий краут-рок
Можно использовать метаданные, которые приходят от правообладателя вместе с треком: жанр, альбом и год выпуска. Жанр — это полезная информация: она не даёт шансону затесаться в рекомендации для любителя классической музыки.
Однако построить таким образом хорошую рекомендацию не выйдет. Во-первых, жанр — это субъективная категория. Во-вторых, существует множество поджанров: обычные люди различают десяток жанров, а правообладатели — несколько тысяч. Их сложно сгруппировать и сложно выбрать среди них похожие, и, к сожалению, эта проблема не всегда решается.

Иногда проблема заключается в ошибках правообладателей. Например, на радиостанции «Рок» мы ставим популярные треки, которые правообладатели отнесли к этому жанру. Иногда к нам обращаются пользователи, которые услышали мелодичный саундтрек на станции, где должен был быть металл, и просят поправить ошибку. Не добавляют простоты каверы и ремиксы. В частности, когда есть оригинальный трек и его кавер, правообладатели не всегда утруждают себя тем, чтобы назвать эти записи по-разному — или даже проставить у них разных исполнителей.
Обычно рекомендации строятся на том, что люди часто прослушивали треки A, B и C вместе: если очередной пользователь прослушивает записи A и B, то ему рекомендуют С. В случае с редкими песнями на помощь разработчикам приходит коллаборативная фильтрация. Она позволяет вычислять похожие записи на основе взаимодействий пользователей с контентом — даже если ни один человек не слушал их вместе.
Коллаборативная фильтрация работает так: нужно составить матрицу оценок пользователей, где по строкам расположатся пользователи, а по столбцам — треки. На пересечении строк и столбцов будут стоять пользовательские оценки: понравился им трек или нет.
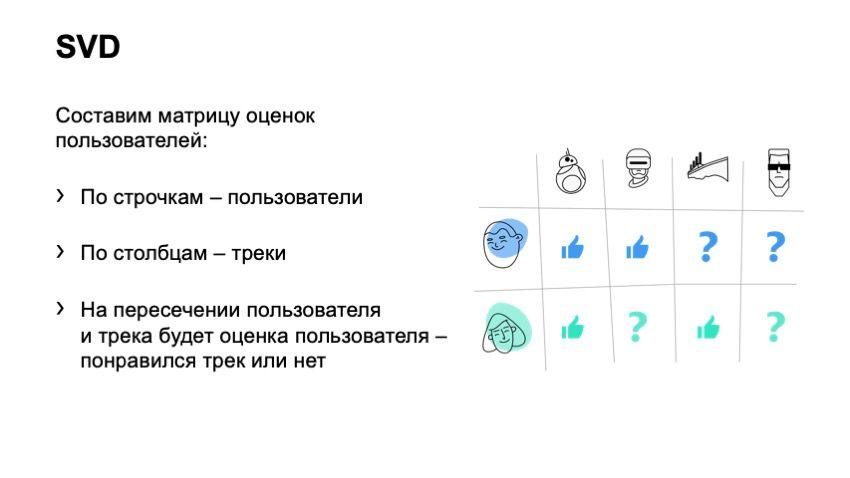
C подобными матрицами возникают две проблемы: во-первых, у них большая размерность — в Яндекс.Музыке можно прослушать сотни тысяч треков. Во-вторых, нам известен пользовательский фидбек только на части матрицы: люди слушают и оценивают небольшую долю мелодий — а по остальным данных нет. Для работы с такими разреженными матрицами разработчики используют сингулярное разложение или SVD.
SVD позволяет сократить размерность матриц. Если R — матрица размера NxM и ранга r, то её можно разложить в произведение матрицы M*r и матрицы r*M, сократив число анализируемых параметров c N*M до (N+M)*r. Так как N и M на практике могут измеряться тысячами, a r обычно меньше десяти, это значительно упрощает работу с данными.
В случае с рекомендательными системами векторы пользователей показывают, насколько им нравится какой-либо фактор, а вектор продукта (в случае с Музыкой — трека) — насколько этот фактор выражен в продукте. Может оказаться, что некоторые из характеристик будут интуитивно понятными: например, для песен выделится темп.
Однако простое сингулярное разложение не работает с треками, которые пока никто не слушал. В таком случае остаётся последний способ — опираться для рекомендаций только на сами мелодии. Для этого нужно получить векторное представление записей и дальше анализировать уже его.
Как представить мелодию в виде векторов
Аудио — это по сути график напряжения: большой набор чисел, с которым неудобно работать. Однако у звука можно проверить спектр и совершить над ним преобразования Фурье: то есть посмотреть, насколько он похож на определённый вид синусоиды.
Но если бы разработчики применяли этот метод для записи в целом, то получили бы мало полезной информации. Это связано с тем, что для музыки важны переходы между частями трека. Однако в спектре они будут видны только в косвенном виде на изменении очень больших частот.
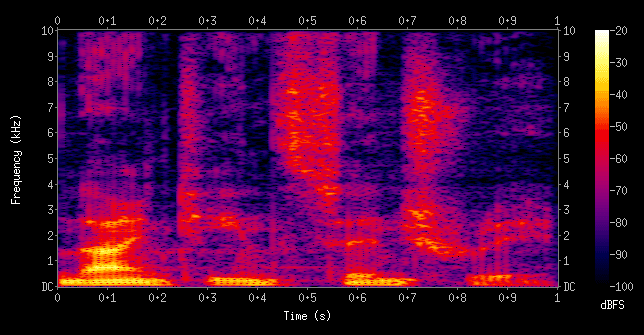
Поэтому для анализа трек разрезается на маленькие кусочки, в каждом из которых производится преобразование Фурье. В результате получается спектрограмма, которая показывает частоты и энергию, которая в определённый момент времени была на каждой отдельной частоте.
Для того, чтобы, используя спектрограмму, получить SVD, можно обучить нейросеть предсказывать такие вектора.
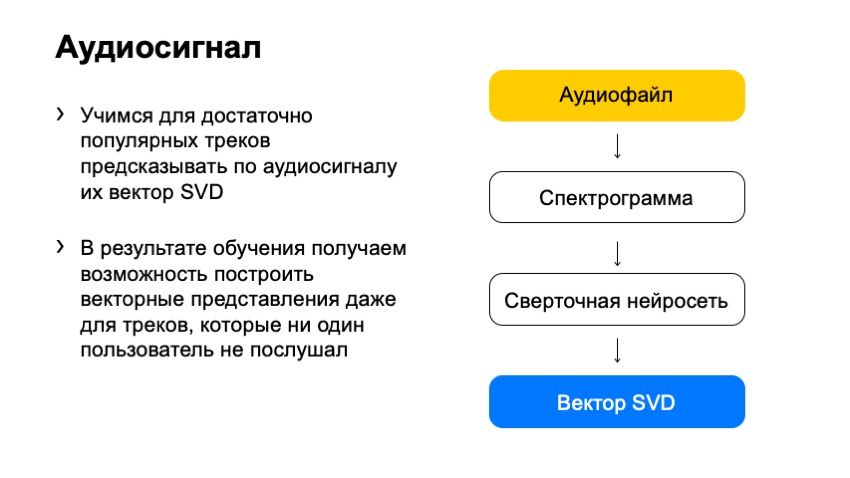
Для обучения нейросети в Яндекс.Музыке отобрали популярные треки, фидбека на которые было достаточно, чтобы точно вычислить их SVD-вектора. В результате получился алгоритм, который может взять любую запись и предсказать её вектор.
Применив этот алгоритм, удалось добиться улучшения рекомендаций в Яндекс.Музыке. За счет него у сервиса получилось удвоить количество новинок, которые он рекомендует пользователям. Пользователи стали приходить чаще и проводить в Музыке больше времени: ежедневное время прослушивания увеличилось на 1,5%. На 7,5% уменьшилось количество дизлайков и жалоб на треки: пользователям реже попадаются треки, которые им не подходят.
