Саша Чубчева изучала прикладную математику и физику в МФТИ, но после лекций ШАДа пришла к Алексею Озёрину писать диплом об одной из классических задач компьютерного зрения. В статье она рассказывает, как алгоритмы анализируют картинки и почему задача сегментации объектов страшна только на первый взгляд.
Как машины видят мир: сегментация изображений в компьютерном зрении

В школе я всегда склонялась к точным наукам — математике и физике, участвовала в выездных школах МФТИ. Туда же и поступила — на факультет управления и прикладной математики. В конце второго курса у нас было распределение по кафедрам, я выбрала базовую кафедру Яндекса, где часть предметов была из ШАДа.
Я слышала, что ШАД — это круто и сложно, и это оказалось правдой. Учёба была непростой, но насыщенной и информативной: много сложных предметов и домашние задания, в которых мы постоянно прокачивали навык написания кода. Окружение, которое сложилось в ШАДе, и полученные знания стоят этих усилий. Я справилась благодаря чёткому планированию и спорту — занималась в секции лёгкой атлетики МФТИ, это позволяло переключиться, «проветрить голову».
Тему про сегментацию я выбрала уже в конце третьего курса. Перед нами выступал мой будущий научный руководитель — Алексей Озёрин, сотрудник Яндекса. Он предложил несколько тем для дипломных работ, среди которых была задача по сегментации глаз. Эта технология помогает обрабатывать изображения в системах биометрии, может использоваться в медицине и при распознавании эмоций, ведь глаза передают эмоциональное состояние человека. При этом важно уметь выделять глаза даже на изображениях плохого качества или с неудачным ракурсом. В рамках дипломной работы мне нужно было изучить научную статью и попытаться воспроизвести предложенный в ней метод сегментации. Целенаправленно компьютерное зрение я не изучала, но предметы ШАДа, которые я посещала, затрагивали машинное обучение — это помогло.
Сейчас я работаю в Яндексе, занимаюсь аналитикой данных в рекламе. Попала сюда через стажировку, а потом осталась работать. Мои задачи сейчас не связаны напрямую с компьютерным зрением, но на деле я всё так же пишу код, применяю знания в области математики, ищу и осваиваю разные методы обработки данных — просто в другом приложении. Так что работа над дипломом была ценной, потому что дала важные навыки и практику работы с данными.
Отрицательный результат — тоже результат
В области компьютерного зрения есть три крупные задачи:
— распознавание: определение наличия на изображении заданных объектов;
— детекция: выделение области изображения, внутри которой находится заданный объект;
— сегментация: выделение силуэта объекта и закрашивание его частей.
В своём дипломном проекте я как раз занималась третьей темой. В случае с сегментацией глаз, модель должна определить и закрасить на изображении зрачок и видимую часть белка глаза.
Я поставила перед собой две задачи: воспроизвести результат из статьи, чтобы понять, почему он получился именно таким, и перенести его на другие классы объектов. Метод обучения, который я использовала — shape constrained network — презентовали в 2019 году. Он позволяет модели качественнее сегментировать неидеальные изображения: глаза, сфотографированные под разными углами, прищуренные, у людей с разной внешностью, на нечётких фотографиях и т. п. Благодаря применению этого метода модель лучше справляется с тем, чтобы найти и выделить на изображении разные участки глаза: зрачок, радужку и видимую часть глазного яблока.
Для начала я изучила метод построения модели и её архитектуру. Самого кода в открытом доступе не было, поэтому я самостоятельно воспроизвела его, чтобы протестировать и выяснить, почему в статье получились именно такие результаты. Дополнительно к уже готовой архитектуре сегментационной нейросети я использовала архитектуру VAE-GAN. Они должны были работать в связке, дополняя друг друга.
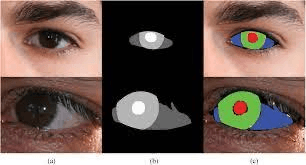
Чтобы понять, насколько модель хорошо справилась с изображениями глаз, я сравнивала три изображения: исходную фотографию, «раскраску», которую разметил человек, и «раскраску», которую разметила модель. Если две «раскраски» совпадают, значит, модель справилась так же хорошо, как и человек.
У меня была светлая мысль: если модель научилась хорошо распознавать глаза на самых разных изображениях, метод сработает и для изображений чего-то ещё, кроме глаз, например для прямоугольных объектов: телевизоров, мониторов и т. п. Светлая мысль оказалась неверной: особого прироста в качестве сегментации прямоугольных объектов метод не дал.
Не могу сказать, что такой результат меня обрадовал, но весь процесс работы над дипломом дал мне представление о том, как происходит обучение моделей под конкретные задачи ML. Одна из проблем, с которой я столкнулась, заключалась в том, что метод, который хорошо справляется с одной задачей, может не справиться с другой. В моём случае метод хорошо работал с изображением глаз, но оказался неприменим для сегментации объектов прямоугольной формы на фотографиях, где объекты перекрывают друг друга. Например, модель не могла вычленить на фото телевизор, перед которым стоит ваза, потому что для неё этот контур объекта не был прямоугольным.
Всего работа над дипломом заняла у меня полгода, и итогом стала презентация, где я показала построенные нейросетью маски и сравнила их с другими, сделанными человеком, выделила метрики качества и рассказала о том, как я воспроизводила метод обучения и с какими сложностями столкнулась, когда попыталась перенести его на другие объекты.
Пара советов для тех, у кого диплом связан с машинным обучением
Машинное обучение развивается стремительно: выходит множество новых статей, физически невозможно уследить за всем. Сложно быть в курсе всего, хотя и хочется. Ещё есть сложность с хорошими датасетами: собирать их долго, трудно и дорого. Поэтому я бы советовала поступить так:
1. Заложить время на работу с данными. Часто для диплома берутся причёсанные датасеты с качественной разметкой, кем-то уже заботливо собранные. Но в жизни приходится работать и с другими данными — шумными, некачественно собранными. Нужно учиться анализировать такие датасеты и видеть в них проблемные места, это пригодится потом на практике.
2. Идти от простого к сложному: воспроизвести метод, описанный в статье, убедиться, что он хорошо работает, и только потом пробовать переносить его на другие объекты. У меня была финальная цель, и я так увлеклась ею, что пропустила важные начальные этапы — тестирование модели на более простых формах, в моём случае — на изображениях глаз. В итоге я всё равно вернулась к этому этапу и только потом смогла заняться более сложной задачей.