Автокорреляционная функция
Временной ряд – зависимые между собой наблюдения. Например, температура воздуха сегодня достаточно сильно зависит от вчерашнего показателя температуры. Эту зависимость хотелось бы описать численно. Для этого часто используют разные виды коэффициентов корреляции, например, корреляции Пирсона, Спирмена и Кендалла. Каждый из этих коэффициентов корреляции вычисляется по двум выборкам, корреляцию между которыми требуется посчитать. В данном случае мы имеем один временной ряд, и наша задача – оценить корреляцию между разными наблюдениями ряда, считая, что она не меняется со временем.
В качестве оценки корреляции значений $y_t$ и $y_{t+\tau}$ для любых $t$ рассмотрим коэффициент корреляции Пирсона ряда с самим собой со сдвигом на $\tau$. Тем самым мы получим численную оценку степени влияния значения $y_t$ на значение $y_{t+\tau}$:
$$r_{\tau} = \widehat{corr}(y_t, y_{t+\tau}) = \frac{\sum\limits_{t=1}^{T-\tau} \left(y_t - \overline{y}\right)\left(y_{t+\tau} - \overline{y}\right)}{\sum\limits_{t=1}^T \left(y_t - \overline{y}\right)^2},$$
где $\tau$ – лаг автокорреляции, а среднее вычисляется по всему ряду $\overline{y} = \frac{1}{T}\sum\limits_{t=1}^T y_t$. Например, если мы хотим оценить степень влияния сегодняшней температуры на завтрашнюю, то посчитаем коэффициент корреляции исходного ряда и им же, сдвинутым на 1 день.
Замечание. Формула содержит некоторые упрощения при оценке ковариации и дисперсий.
Свойства коэффициента корреляции:
- $\vert r_{\tau}\vert \leqslant 1$;
- $r_{\tau} = 0$ – отсутствие автокорреляции, при этом значения могут быть зависимыми (см. подробнее про разницу между независимостью и некоррелированностью);
- $r_{\tau} > 0$ – положительная корреляция, то есть чем больше было значение вчера, тем оно будет больше сегодня;
- $r_{\tau} < 0$ – отрицательная корреляция, то есть чем больше было значение вчера, тем оно будет меньше сегодня;
- $\vert r_{\tau} \vert = 1$ означает строгую линейную зависимость.
Посмотреть простые примеры и потренировать свою интуицию вы можете в игре Guess The Correlation.
Пусть мы посчитали значение автокорреляции. А как понять, значение 0.1 – это много или мало? На этот вопрос может ответить статистический критерий Льюнга-Бокса (Ljung–Box), который проверяет значимость отклонения $r_{\tau}$ от нуля. Основное правило, которое нужно здесь понять – если значение p-value критерия не превосходит $0.05$ (или другого заранее фиксированного порога значимости), то автокорреляция с лагом $\tau$ значима. Это число вычисляется с помощью стандартных статистических пакетов (например, statsmodels в Питоне).
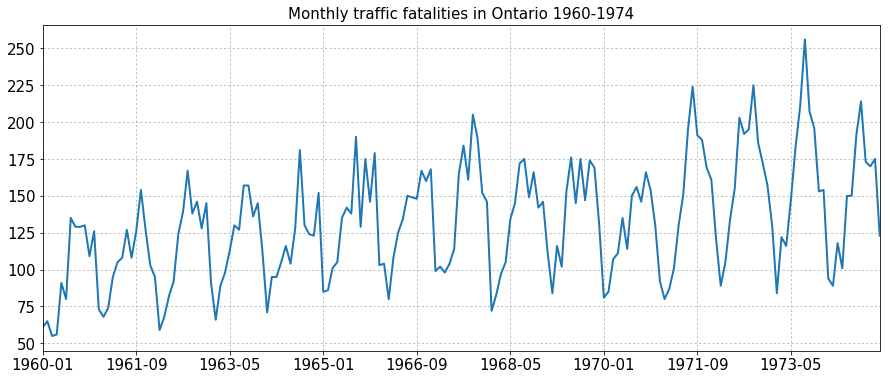
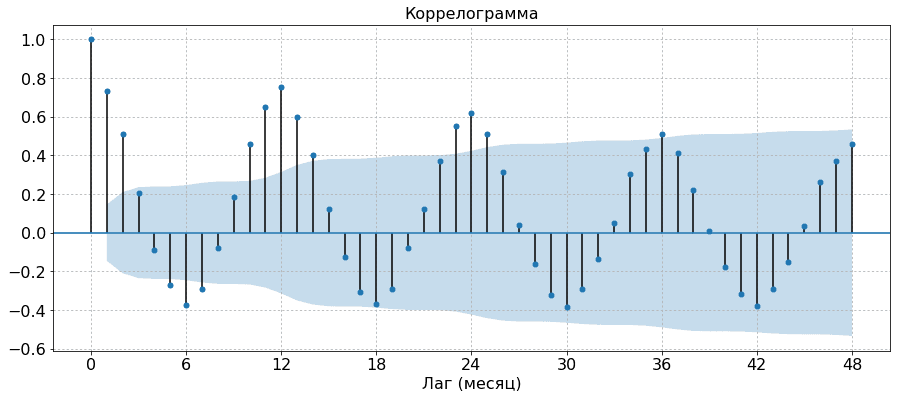
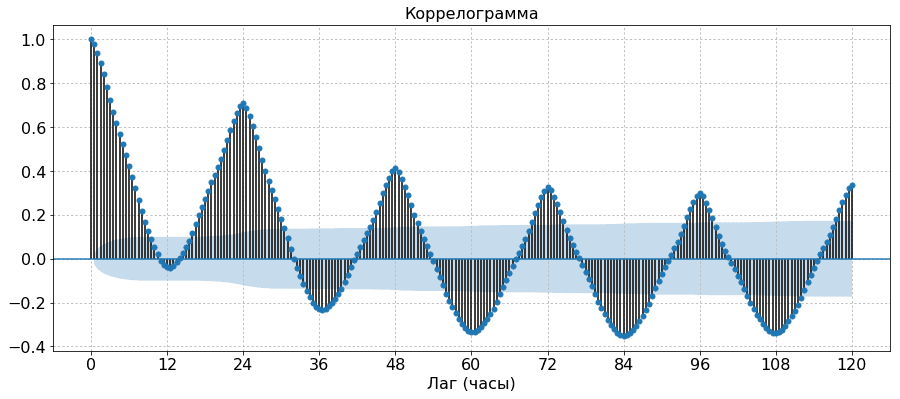
Рассмотрим временной ряд дорожно-транспортных происшествий за 14 лет с дискретностью 1 месяц, то есть с 12 измерениями в год. На графике мы видим явную сезонность. На нижнем графике изображена коррелограмма – график, визуализирующий автокорреляционную функцию. Точками на графике показаны значения автокорреляционной функции. Ее значение в нуле всегда равно 1, так как это автокорреляция ряда с собой же. Также мы видим, что значение $r_{12}$ является локальным максимумом, что означает высокую положительную корреляцию значения ряда за текущий месяц с аналогичным значением год назад. Иными словами, ряд со сдвигом на год ведёт себя «похожим образом», и это подкрепляет наше наблюдение про наличие годичной сезонности. Наоборот, значение $r_{6}$ минимально в своей окрестност и, что означает высокую отрицательную корреляцию значения ряда со значением полгода назад. Закрашенная область визуализирует границу незначимой автокорреляции, то есть тех значений автокорреляции, для которых не выявлена статистически значимое отличие от 0 (иначе говоря, доверительный интервал пересекает 0). Так мы видим, что последняя значимая сезонная автокорреляция это – это $r_{24}$. Кроме нее также значима сезонная корреляция $r_{12}$ и корреляция за половину сезона $r_6$. Из несезонных автокорреляций значимы оказались $r_{1}$ и $r_{2}$. Отсюда можно сделать вывод, что для построения прогноза значения $y_t$ имеет смысл рассматривать признаки $y_{t-1}, y_{t-2}, y_{t-6}, y_{t-12}, y_{t-24}$.
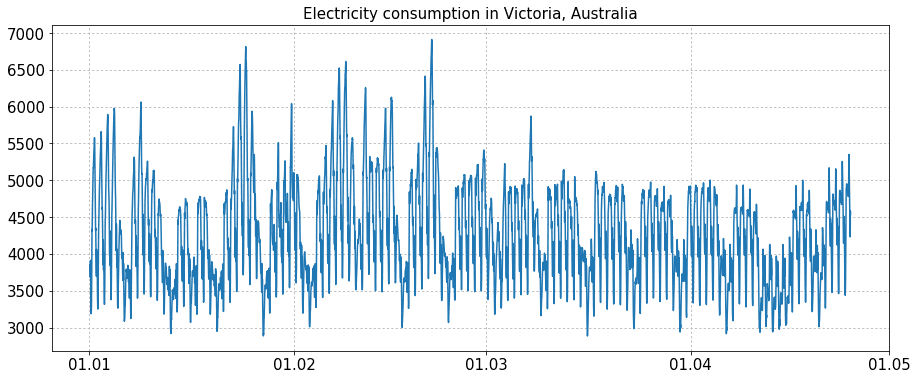
Рассмотрим временной ряд потребления электричества в Австралии с дискретностью 30 минут. По графику мы можем заметить две разных сезонности – суточную и недельную. Кроме того, при наличии большего количества данных мы смогли бы увидеть еще и годовую сезонность. На данном графике видно повышенное потребление электричества в январе-феврале, когда в Австралии жарко и работает много кондиционеров. По графику автокорреляций мы видим, что наибольшую корреляцию имеют соседние измерения, а также значения сутки назад, двое суток назад, и т.д. Наоборот, значения 12, 36, ... часов назад имеют отрицательную корреляцию.
Стационарные временные ряды
Временной ряд $y_t$ называется стационарным
- в узком смысле, если для любых $\ t_1, ..., t_n, \tau$ вектор $(y_{t_1+\tau}, ..., y_{t_n+\tau})$ совпадает по распределению с $(y_{t_1}, ..., y_{t_n})$, то есть при сдвиге всех моментов времени на одно и тоже число совместное распределение значений временного ряда в эти моменты времени не поменяется.
- в широком смысле, если
- $\mathbb{E} y_t^2 < +\infty$ для любого $t$.
- $\mathbb{E} y_t$ не зависит от $t$, то есть в среднем значение временного ряда постоянно.
- $cov(y_{t+\tau}, y_{s+\tau}) = cov(y_{t}, y_{s})$ для любых $t, s, \tau$, то есть значение автокорреляции зависит только от длины отрезка времени между двумя значениями.
- для гауссовских распределений, то есть для случая, когда все векторы вида $(y_{t_1}, ..., y_{t_n})$ имеют нормальное распределение, определения эквивалентны. Это следует из того, что распределение гауссовского случайного вектора полностью определяется математическим ожиданием и ковариациями.
Пример. Рассмотрим временной ряд $y_t = \xi_1 \cos t + \xi_2 \sin t$, где $\xi_1, \xi_2$ и независимы и одинаково распределены, причем $\mathsf{P}(\xi_1=1) = \mathsf{P}(\xi_1=-1) = 1/2$.
Можем заметить, что $\mathbb{E} y_1 = 0$ и $cov(y_t, y_s) = \cos t\cos s\ \mathsf{D} \xi_1 + \sin t\sin s\ \mathsf{D} \xi_2 = \cos (t-s)$. Тем самым имеем стационарность в широком смысле.
Но при $t=0$ получаем $y_0 = \xi_1 \in {-1, 1}$, а при $t = \pi/4$ получаем
$$y_{\pi/4} = \frac{\xi_1 + \xi_2}{\sqrt{2}} \in \left\{-\sqrt{2}, 0, \sqrt{2}\right\}.$$
Мы получили разные распределения, поэтому нет стационарности в узком смысле.
Некоторые примеры нестационарных временных рядов:
- Случайное блуждание – пример: $y_t = y_{t-1} + \varepsilon_t$, где $\varepsilon_t$ – белый шум, то есть независимые одинаково распределенные случайные величины. Математическое ожидание постоянно, но ряд не является стационарным, поскольку $\mathsf{D} y_t$ бесконечно растет.
- Временной ряд с трендом – пример: $y_t = \alpha + \beta t + \varepsilon_t$, где $\varepsilon_t$ – белый шум. Ряд не стационарен, так как $\mathbb{E} y_t$ меняется с течением времени.
- Временной ряд с сезонностью – пример: $y_t = \sin t + \varepsilon_t$, где $\varepsilon_t$ – белый шум. Не стационарен, так как
$$\mathbb{E} y_t=\begin{cases} -1, \text{ при }t = -\pi/2 + 2\pi k; \ 1, \text{ при }t = t = \pi/2 + 2\pi k. \end{cases}$$
Стационарный ряд визуально не имеет предсказуемых закономерностей. Если посмотреть на график такого ряда издалека, то он будет горизонтален.
Ряд можно проверить строго на станционарность с помощью различных статистических критериев. Наиболее популярны следующие критерии:
- критерий KPSS (Kwiatkowski–Phillips–Schmidt–Shin): если p-value $\leqslant 0.05$, то отвергаем стационарность;
- критерий Дики-Фуллера: если p-value $\leqslant 0.05$, то отвергаем \textbf{НЕ}стационарность.
Рассмотрим несколько примеров временных рядов:
- ряды а, c, d, e, f, i не стационарны, поскольку они имеют тренд;
- ряд b скорее всего стационарный, имеется выброс;
- ряды d, g, h, i не стационарны, потому что имеют сезонность.
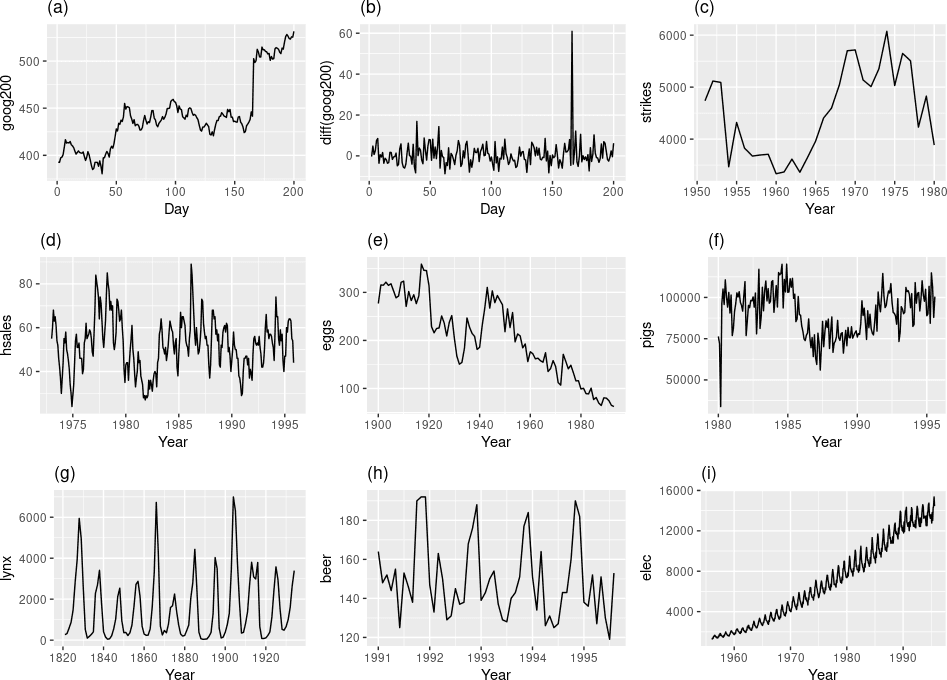
Когда вы определяете, чем вызвано изменение данных – трендом или шумом – стоит учитывать природу данных. Например, колебания значений ряда f теоретически можно было бы объяснить шумом в данных, но по временной оси мы видим, что данные представлены за 15 лет, соответственно, понимаем данные колебания как изменения тренда. Аналогично, для ряда d мы говорим о наличии меняющегося тренда помимо годовой сезонности.
Приведение к стационарным: стабилизация дисперсии
Зачем?
Данные методы рекомендуется использовать, если задача требует некоторой аналитики временного ряда. Если же требуется только построить точечный прогноз на будущее без построения предсказательных интервалов, то стабилизация дисперсии не является необходимой процедурой. Если же нас интересует предсказательный интервал, то многие методы лучше обрабатывают именно стационарные ряды, поэтому имеет смысл стабилизировать дисперсию.
Преобразования:
Класс преобразований Бокса-Кокса с параметром $\lambda$:
$$z_t = \begin{cases} \ln y_t, & \lambda = 0 \ (y_t^\lambda - 1) / \lambda, & \lambda \not=0 \end{cases}.$$
Если есть предположения о зависимости $\mathsf{D} y_t$ от $t$, то можно рассмотреть ряд $z_t = y_t \left/ \sqrt{\mathsf{D} y_t} \right.$.
После построения прогноза для преобразованного ряда нужно сделать обратное преобразование.
Приведение к стационарным: тренд и сезонность
Преобразования:
Дифференцирование ряда, то есть переход к ряду $(y'_t, t \in \{2, ..., T\})$, где $y'_t = y_t - y_{t-1}$. Данное преобразование используется для снятие тренда.
Сезонное дифференцирование ряда, то есть переход к ряду $(y'_t, t \in \{s+1, ..., T\})$, где $y'_t = y_t - y_{t-s}$, $s$ – длина сезона.
Преобразования можно применять несколько раз. Обычно сначала применяют сезонное дифференцирование.
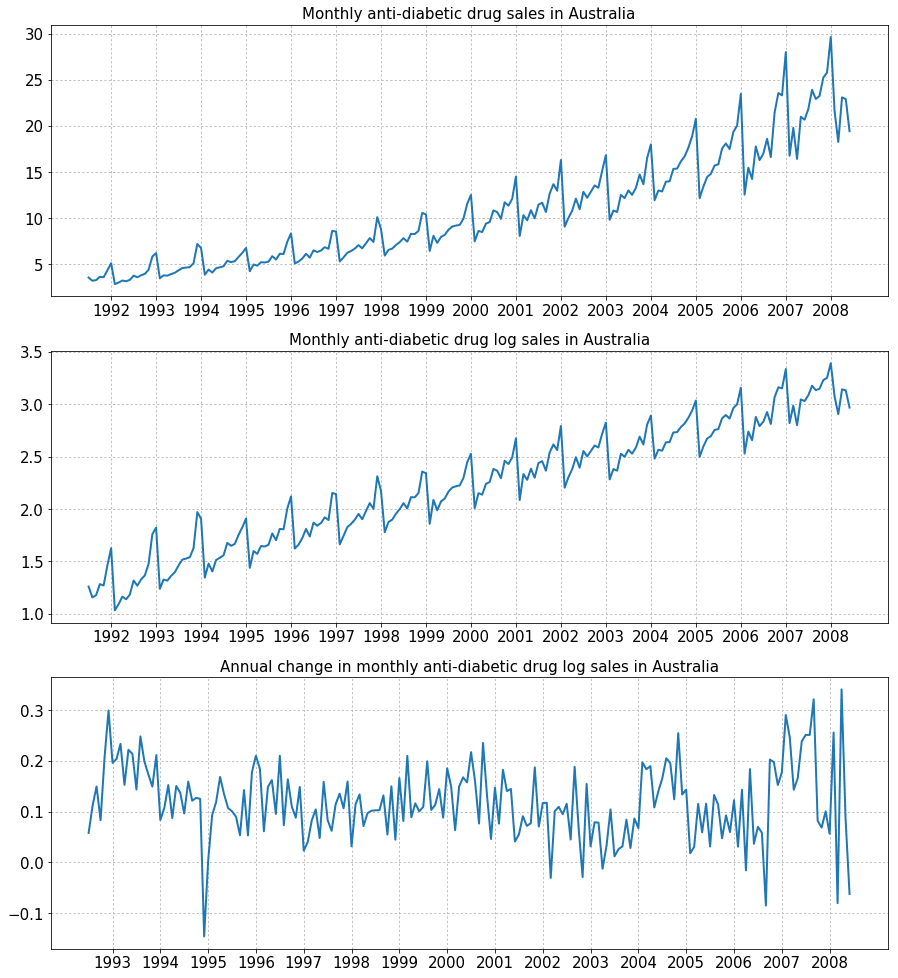
Посмотрим на пример. В критерии KPSS для исходного ряда $pvalue < 0.01$, то есть ряд можно считать нестационарным. После логарифмирования ряда $pvalue < 0.01$, а после ещё и сезонного дифференцированная $pvalue > 0.1$, тем самым полученный ряд мы уже не можем отличить от стационарного.
Модели вида экспоненциального сглаживания
Простое экспоненциальное сглаживание
Не редко временной ряд выглядит довольно шумным, что может достаточно плохо сказаться на работе других моделей и подходов к анализу этого временного ряда. В таком случае можно попытаться сгладить значения ряда. Далее мы рассмотрим несколько моделей сглаживания ряда, в том числе при наличии тренда и сезонности ряда. Помимо сглаживания истории ряда, с помощью данных методов можно также осуществлять простое прогнозирование ряда.
Пусть имеется временной ряд $y_t$. В результате экспоненциального сглаживания получается новый временной ряд $\widehat{y}$ по правилу
$$\widehat{y}_{t+1\vert t} = \alpha y_t + (1 - \alpha) \widehat{y}_{t\vert t - 1},$$
где $\widehat{y}_{t+h\vert t}$ – прогноз значения $y_{t+h}$ в момент времени $t$, а $\alpha$ – *параметр сглаживания*.
Смысл преобразования следующий – сглаженное значение в момент времени $t+1$ есть взвешенная комбинация предыдущего значения ряда $y_t$ и предыдущего сглаженного значения ряда $\widehat{y}_{t\vert t - 1}$.
Свойства:
- при $\alpha \approx 1$ больший вес последнему значению ряда, поэтому получается слабое сглаживание $\widehat{y}_{T+1\vert T} \approx y_T$;
- при $\alpha \approx 0$ больший вес отдается предыдущему сглаженному значению, и получается сильное сглаживание, что в пределе вырождается в среднее $\widehat{y}_{T+1\vert T} \approx \overline{y}$;
- Оптимальное значение $\alpha^{\ast}$ можно подобрать либо по графику, либо оптимизируя
$$\sum\limits_{t=t_0}^T \left(\widehat{y}_{t}(\alpha) - y_t\right)^2 \to \min_{\alpha}.$$
Существуют следующие эмпирические правила:
- если $\alpha^{\ast} \in (0, 0.3)$ то ряд стационарен, можно применять экспоненциальное сглаживание без риска большой потери информации;
- если $\alpha^{\ast} \in (0.3, 1)$ то ряд нестационарен, применение экспоненциального сглаживания может привести к потере информации или смещению.
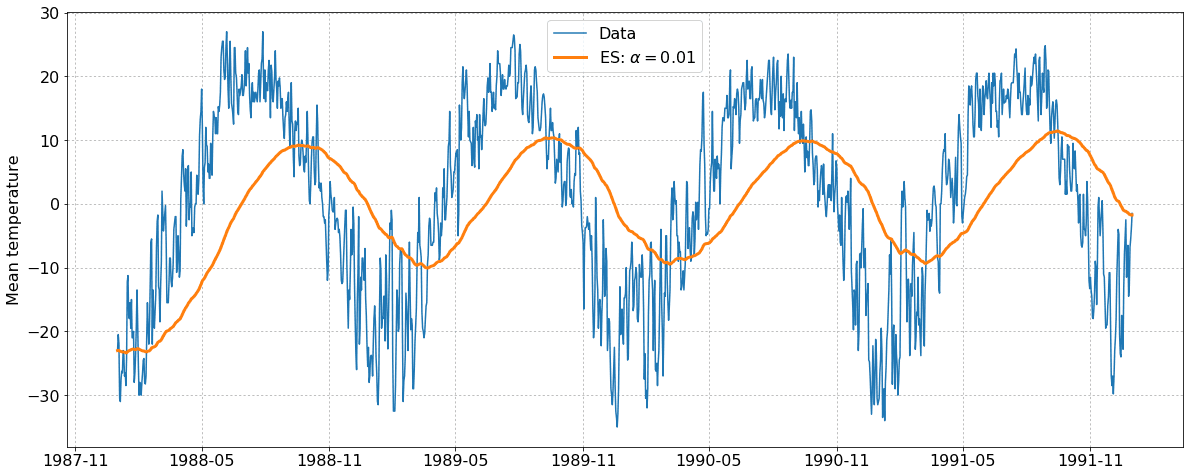
Примеры: на каждом из графиков изображен исходный ряд (синий) и сглаженный ряд (оранжевый) для разных значений параметра сглаживания. Если имеется тренд или сезонность, то при большом сглаживании полученный ряд начинает «запаздывать» за исходным рядом.
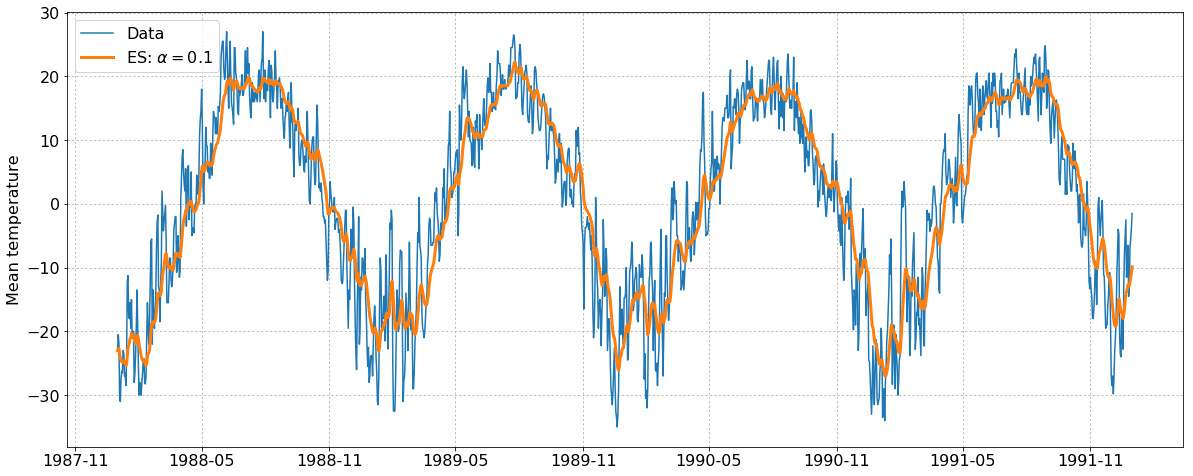
Откуда взялась эта формула экспоненциального сглаживания?
Покажем, что сглаженное значение соответствует прогнозу величины $x$ в момент времени $T+1$, подбираемому по правилу
$$\sum\limits_{t = 0}^T\beta^{T - t}(y_{t} - x)^2 \rightarrow \min\limits_x.$$
Иначе говоря, для прогнозирования мы берем взвешенный MSE с экспоненциально убывающими по времени весами.
Приравняем производную к нулю:
$$2\sum\limits_{t = 0}^T\beta^{T - t}(y_{t} - x) = 0$$
Отсюда выразим $x$ и воспользуемся разложением функции $\frac{1}{1-x}$ в ряд Тейлора
$$x = \dfrac{\sum\limits_{t = 0}^{T}\beta^{T - t}y_t}{\sum\limits_{t = 0}^{T}\beta^t} \approx \dfrac{\sum\limits_{t = 0}^{T}\beta^{T - t}y_t}{1/(1 - \beta)} =(1 - \beta) \sum\limits_{t = 0}^T\beta^{T - t}y_t =$$
$$ = (1 - \beta) y_T + (1 - \beta) \beta \sum\limits_{t=0}^{T - 1}\beta^{T - 1 - t}y_t = (1 - \beta)y_T + \beta \widehat{y}_{T|T - 1}$$
Тем самым мы получили модель экспоненциального сглаживания для $\beta = 1 - \alpha$.
Модель Хольта
Аддитивный линейный тренд:
Прогноз на $d$ шагов вперед выражается с помощью линейной функции от числа шагов, где коэффициенты меняются по формулам, аналогичным экспоненциальному сглаживанию
$$\widehat{y}_{t+d|t} = a_t + b_t \cdot d,$$
$$a_t = \alpha y_t + (1-\alpha) (a_{t-1} + b_{t-1})$$
$$b_t = \beta (a_t - a_{t-1}) + (1-\beta) b_{t-1}$$
Модель для мультипликативного линейного тренда выглядит аналогично
$$\widehat{y}_{t+d|t} = a_t b_t^d,$$
$$a_t = \alpha y_t + (1-\alpha) (a_{t-1} b_{t-1})$$
$$b_t = \beta \frac{a_t}{a_{t-1}} + (1-\beta) b_{t-1}$$
Модель Хольта: пояснение формул
Поясним на примере аддитивного тренда, почему формулы для $a_t$ и $b_t$ получаются именно такими.
Заметим, что для $d=0$ и $d=1$ и момента времени $t+1$ получаем $\widehat{y}_{t + 1\vert t + 1} = a_{t + 1}$, $\widehat{y}_{t + 1\vert t} = a_{t} + b_{t}$. Хотелось бы, чтобы эти прогнозы примерно совпадали, то есть чтобы имело место $a_{t + 1} - a_{t} \approx b_{t}$.
Рассмотрим ряд разностей $\Delta y_t = a_{t + 1} - a_{t}$ и задачу константного прогноза для него (то есть $\Delta \widehat{y}_{t \vert t - 1} = b$) методом простого экспоненциального сглаживания
$$\sum\limits_{i = 0}^{t}(1 - \beta)^{t - i}(\Delta y_i - b)^2 \rightarrow \min_b.$$
Ее решение мы уже получили ранее:
$$b_t = \beta \Delta y_{t - 1} + (1 - \beta)b_{t - 1} = \beta (a_t - a_{t-1}) + (1-\beta) b_{t-1}.$$
Получилась формулу для $b_t$ в модели аддитивного тренда.
Далее, мы хотим, чтобы имело место $a_{t + 1} \approx b_{t} + a_{t}$. Рассматривая для $y_t$ экспоненциальное сглаживание, в котором в качестве предыдущего значения сглаженного ряда берется $b_t+a_t$, а в качестве нового – $a_{t + 1}$, получаем
$$a_t = \alpha y_t + (1-\alpha) (a_{t-1} + b_{t - 1}).$$
Модель Хольта-Уинтерса
Аддитивная сезонность с трендом:
$$\widehat{y}_{t+d|t} = a_t + db_t + s_{t-m+(d \text{ mod } m)},$$
$$a_t = \alpha (y_t - s_{t-m}) + (1-\alpha) (a_{t-1} + b_{t-1})$$
$$b_t = \beta (a_t - a_{t-1}) + (1-\beta) b_{t-1}$$
$$s_t = \gamma(y_t - a_t) + (1-\gamma)s_{t-m}$$
где $m$ – длина сезона
Мультипликативная сезонность
Без тренда
$$\widehat{y}_{t+d|t} = a_t \cdot s_{t-m+(d \text{ mod } m)},$$
$$a_t = \alpha (y_t / s_{t-m}) + (1-\alpha) a_{t-1}$$
$$s_t = \gamma(y_t / a_t) + (1-\gamma)s_{t-m}$$
С линейным трендом
$$\widehat{y}_{t+d|t} = (a_t + db_t) s_{t-m+(d \text{ mod } m)},$$
$$a_t = \alpha \frac{y_t}{s_{t-m}} + (1-\alpha) (a_{t-1} + b_{t-1})$$
$$b_t = \beta (a_t - a_{t-1}) + (1-\beta) b_{t-1}$$
$$s_t = \gamma\frac{y_t}{a_t} + (1-\gamma)s_{t-m}$$
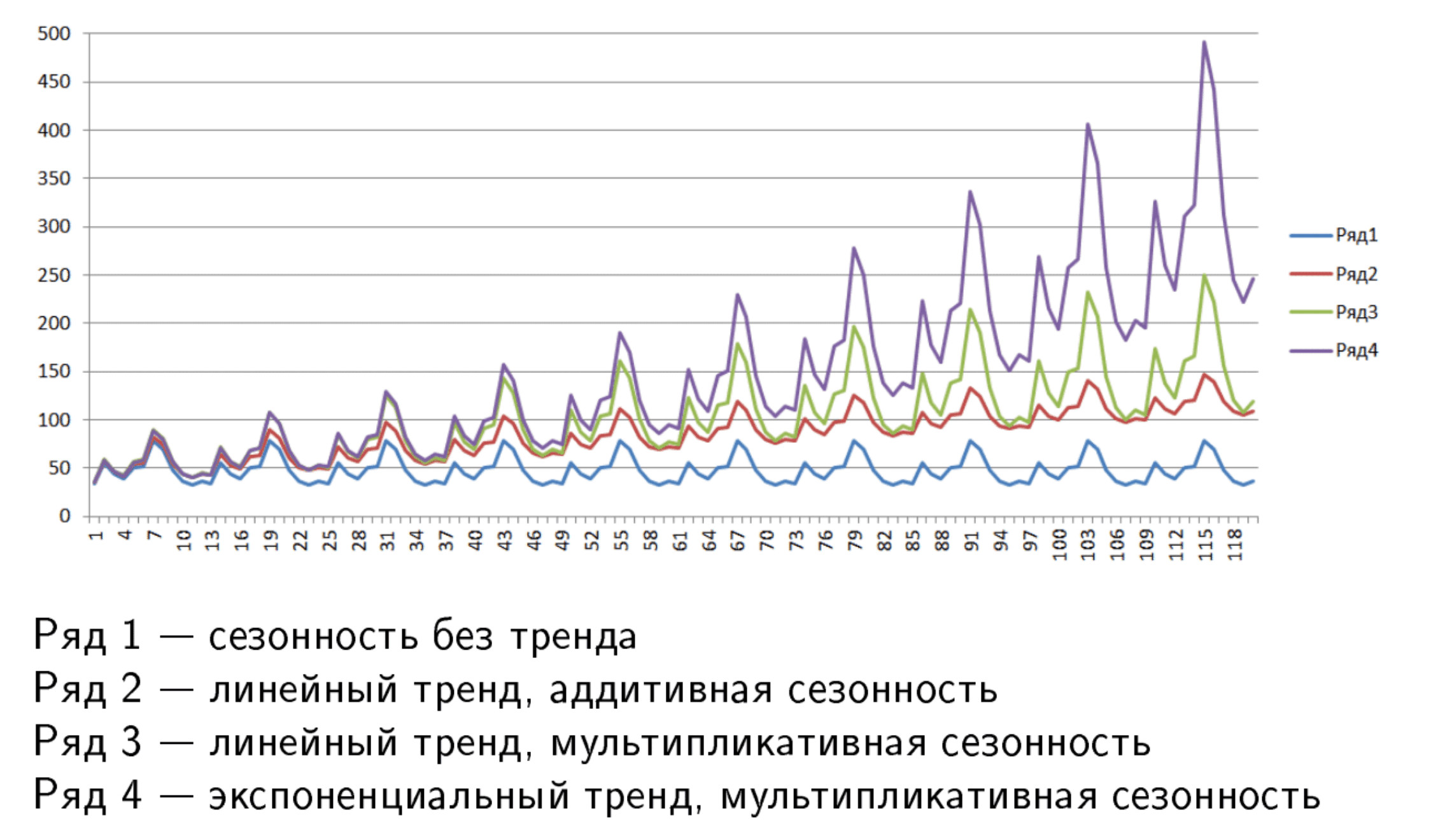
Разные модели с трендом и сезонностью
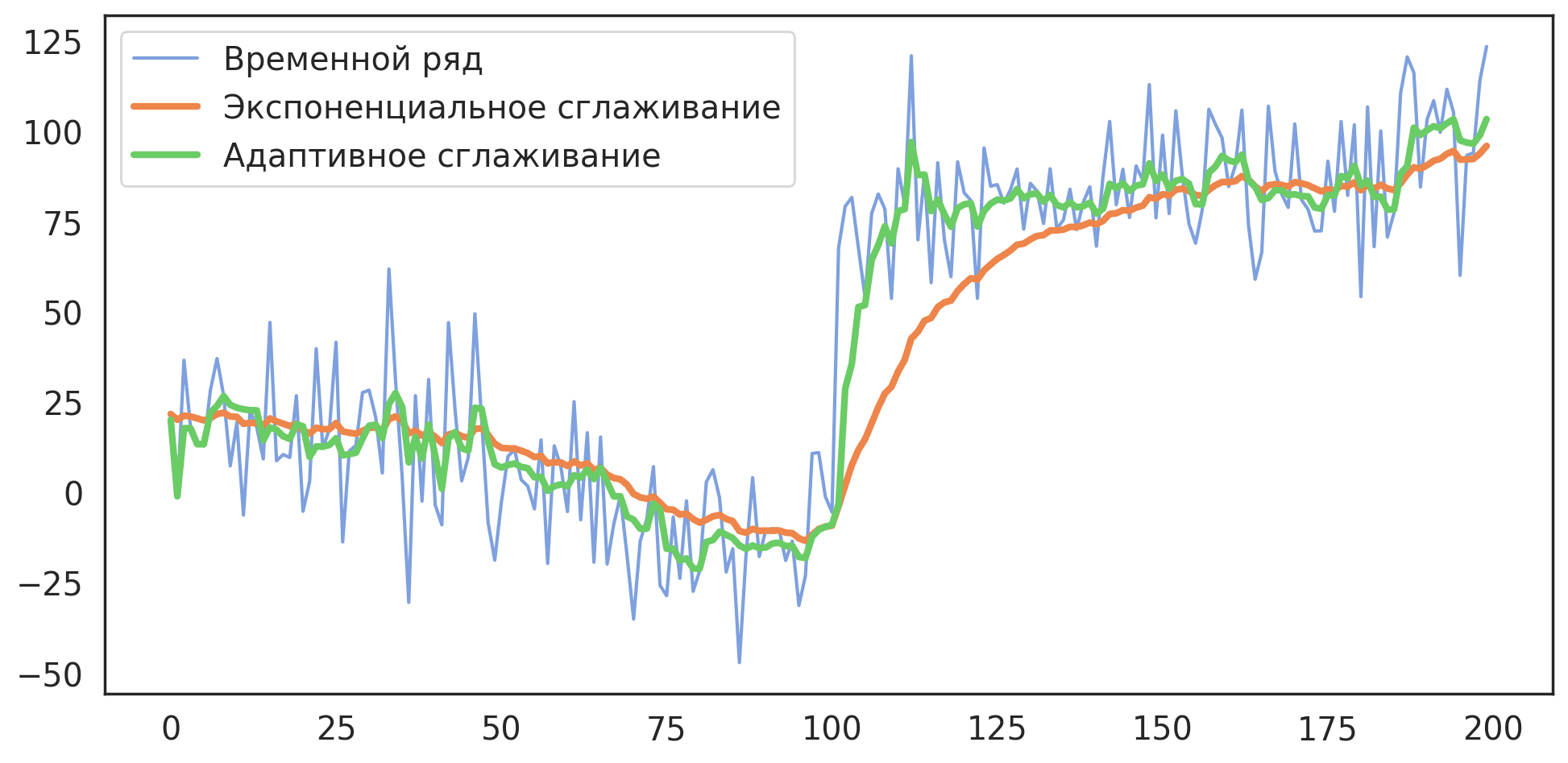
Адаптивное сглаживание
В примерах выше мы видели, что при изменении локального тренда ряда экспоненциальное сглаживание запазывает за значениями ряда при использовании сильного сглаживания. Если же использовать слабое сглаживание, то существенного запаздывания не проиходит, но ряд остается шумным. Если для ряда предполагаются значительные структурные изменения, можно использовать модель адаптивного экспоненциального сглаживания, в которой параметр сглаживания может меняться для разных отрезков временного ряда.
Пусть $\widehat{y}_t$ – прогноз значения $y_t$ в момент времени $t-1$ обычным экспоненциальным сглаживанием, а $\widehat{\varepsilon}_t = y_t - \widehat{y}_t$ – ошибка прогноза, сделанного на шаге $t-1$.
Определим следующие значения
- Среднее значение ошибки:
$$E_t = \gamma \widehat{\varepsilon}_t + (1-\gamma)E_{t-1}.$$
- Средний разброс ошибки:
$$A_t = \gamma \left|\widehat{\varepsilon}_t\right| + (1-\gamma)A_{t-1}.$$
- $K_t = E_t/A_t$ – статистика, которая сигнализирует, насколько адекватно модель работает в момент времени $t$.
- $K_t \approx \pm 1$ – модель систематически ошибается в одну сторону.
- $K_t \approx 0$ – модель работает адекватно.
Обычно берут значения $\gamma \in (0.05, 0.1)$. Чтобы экспоненциальное сглаживание быстро приспосабливалось к резким структурным изменениям берут $\alpha_t = \min \left(|K_t|, 1\right)$.
Однако, у данного подхода есть и недостатки, например,
- плохо реагирует на одиночные выбросы;
- требует подбора $\gamma$.