



Вы нашли несколько золотых слитков. Ваша цель — положить как можно больше золота в рюкзак вместимостью $W$ фунтов. Каждый слиток существует только в одном экземпляре. При этом можно либо взять слиток целиком, либо не брать его вовсе. И хотя все слитки на рисунке выше выглядят одинаково, они обладают разным весом — он приведён ниже.

Естественная «жадная» стратегия — взять самый тяжелый слиток, на который хватает вместимости рюкзака, и повторно проверить, а осталось ли место на ещё один слиток.
При наборе слитков, приведённом выше, и рюкзаке вместимостью $20$ «жадный» алгоритм выбирает слитки весом $10$ и $9$. Однако оптимальное решение — использовать слитки весом 4, 6 и 10!
- Входные данные: Первая строка ввода содержит целое число $W$ (вместимость рюкзака) и количество золотых слитков $n$. В следующей строке приведены $n$ целых чисел $w_1,\dotsc,w_{n}$, которые определяют вес золотых слитков.
- Выходные данные: Максимальный вес золотых слитков, который можно уместить в рюкзак вместимостью $W$.
- Ограничения: $1 \le W \le 10^4$; $1 \le n \le 300$; $0 \le w_1,\dotsc,w_{n} \le 10^5$.
Пример 1
| Ввод | Вывод |
|---|---|
| 10 3 1 4 8 | 9 |
Сумма веса первого и последнего слитков равна $9$.
✒️ Упражнение:
Продемонстрируйте, как можно использовать это решение для выполнения задачи «Максимальное количество золота».
Предположим, что заполнить рюкзак до конца действительно возможно: существует набор $S \subseteq {w_0, \dotsc, w_{n-1}}$ с общим весом $W$. Включает ли он в себя последний слиток с весом $w_{n-1}$?
- Случай 1: Если $w_{n-1} \not \in S$, тогда рюкзак вместимостью $W$ может быть заполнен первыми $n-1$ слитками.
- Случай 2: Если $w_{n-1} \in S$, тогда мы можем убрать слиток с весом $w_{n-1}$ из рюкзака, и вес оставшихся слитков составит $W-w_{n-1}$. Таким образом, рюкзак с вместимостью $W-w_{n-1}$ можно полностью заполнить первыми $n-1$ слитками.
В обоих случаях мы свели задачу к практически такой же, но с меньшим количеством слитков и меньшей вместимостью рюкзака. Так, переменная $pack(w, i)$ будет иметь значение ${\tt true}$, если существует возможность заполнить рюкзак с вместимостью $w$ первыми $i$ слитками, и значение ${\tt false}$ в остальных случаях. Анализ двух вышеприведённых случаев приводит нас к следующему рекуррентному соотношению для $i>0$: $$ pack(w,i)=pack(w,i-1) \text{ или } pack(w-w_{i-1},i-1) . $$
Обратите внимание, что при $w_{i-1} > w$ второе выражение не имеет смысла.
Кроме того, $pack(0, 0) = {\tt true}$ и $pack(0,w) = {\tt false}$ для любого $w > 0$.
В целом
Так как значения $i$ варьируются между 0 и $n$, а значения $w$ — между 0 и $W$, мы имеем $O(nW)$ переменных. Так как $pack(w,i)$ зависит от $pack(w,i-1)$, мы обрабатываем все переменные в возрастающем порядке $i$. В приведённом ниже псевдокоде мы используем двумерный массив pack размера $(W+1) \times (n+1)$, а $pack[w][i]$ сохраняет значение $pack(w,i)$. Время выполнения данного решения составляет $O(nW)$.
Knapsack([w[0],…,w[n−1]],W):
pack = two-dimensional array of size (W+1)×(n+1)
initialize all elements of pack to false
pack[0][0] = true
for i from 1 to n:
for w from 0 to W:
if w[i-1] > w:
pack[w][i] = pack[w][i−1]
else:
pack[w][i]←pack[w][i−1] OR pack[w−w[i−1]][i−1]
return pack[W][n]
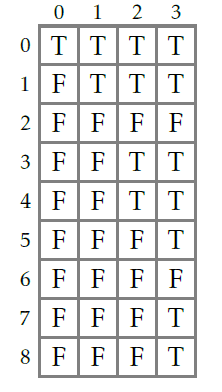
В приведённой ниже двумерной таблице представлены результаты вызова Knapsack([1,3,4], 8. F и T означают значения false и true.
Другое решение будет заключаться в анализе поднаборов всех слитков. Наша цель — найти поднабор из $n$ слитков с общим весом $W$. Простой подход к такой задаче — просматривать все поднаборы и проверять, есть ли поднабор с весом $W$. Так как каждый слиток можно или пропустить, или взять, каждый поднабор из трёх слитков, который мы анализируем ($w_0 = 1$, $w_1 = 3$, $w_2 = 4$), можно представить сине-красным бинарным вектором:

Теперь мы представим каждый поднабор слитков как путь, начинающийся от узла $(0,0)$ сетки $(n+1)\times (W+1)$. Если первый бит — синий, то он соответствует синему горизонтальному сегменту сетки, связывающему $(0,0)$ с $(0,1)$. Если первый бит — красный, то он соответствует красному сегменту сетки, связывающему $(0,0)$ с $(1,w_0)$. Обработав первые $i$ битов, мы получаем сине-красный путь от $(0,0)$ до некого узла $(i,w)$ на сетке. Если следующий бит — синий, мы связываем $(i,w)$ с $(i+1,w)$. Если следующий бит — красный, мы связываем $(i,w)$ с $(i+1,w+w_i)$, как показано ниже для вектора 101:

Рисунок ниже демонстрирует пути, которые соответствуют всем восьми бинарным векторам с длиной 3.

Теперь мы накладываем все эти восемь путей на одну сетку:

Мы классифицируем узел $(i,w)$ на сетке как истинный («true») при наличии пути от $(0,0)$ к $(i,w)$ на рисунке выше. В других случаях — ложный («false»). Теперь мы можем полностью заполнить рюкзак с вместимостью $w$ поднабором из первых $i$ слитков, если узел $(i,w)$ — истинный («true»). Узел будет истинным в случаях, если в него проходит или синее, или красное ребро. То есть, если $(i-1,w)$ или $(i-1,w-w_{i-1})$ истинны. Это наблюдение приводит нас к предыдущему рекуррентному соотношению и к такому же решению с динамическим программированием.
А вот ещё один вариант решения, который основан на мемоизации. Приведённый ниже псевдокод рекурсивно вычисляет рекуррентное соотношение из решения 1:
RecursiveKnapsack([w[0],…,w[n−1]],w,i):
if i=0 and w=0:
return true
else if i=0 and w>0:
return false
else if i>0 and w_[i-1]>w:
return RecursiveKnapsack([w[0],…,w[n−1]],w,i−1)
else:
return RecursiveKnapsack([w[0],…,w[n−1]],w,i−1) OR RecursiveKnapsack([w[0],…,w[n−1]],w−w[i−1],i−1)
Вызов RecursiveKnapsack([w_0, ..., w_{n-1}],W, n) решает задачу, но он сильно замедлен из-за необходимости перевычислять одни и те же значения снова и снова. Чтобы это продемонстрировать, рассмотрим рюкзак с вместимостью $W=4$ и $n=3$ слитков с весом $w_0=1$, $w_2=1$, $w_3=1$. Вызов RecursiveKnapsack([1, 1, 1], 4, 3) создаёт рекурсивное дерево, приведённое ниже — каждый узел показывает значения $(w,i)$.
Даже в этом простом примере значение $(w,i)=(3,1)$ вычисляется дважды. С 20 слитками рекурсивное дерево может достичь гигантских размеров — одно и то же значение может вычисляться миллионы раз.

Во избежание такого рекурсивного взрыва мы «оборачиваем» код мемоизацией с помощью ассоциативного массива $pack$, который изначально пуст. Ассоциативный массив — это абстрактный тип данных, в котором хранятся пары $key, value$. Он поддерживается многими языками программирования и, как правило, реализуется как хеш-таблица или дерево поиска. К примеру, в C++ и Java ассоциативный массив называется картой («map»), а в Python — словарём («dictionary»). В реализации, приведённой ниже, ассоциативный массив $pack$ используется для хранения логических значений для пар $(w, i)$.
MemoizedKnapsack([w[0],…,w[n−1]],pack,w,i):
if (w,i) is not in pack:
if i=0 and w=0:
pack[(w,i)] = true
else if i=0 and w>0:
pack[(w,i)] = false
else if i>0 and w_[i-1]>w:
pack[(w,i)] = MemoizedKnapsack([w[0],…,w[n−1]],pack,w,i−1)
else:
pack[(w,i)] = MemoizedKnapsack([w[0],…,w[n−1]],pack,w,i−1) OR MemoizedKnapsack([w[0],…,w[n−1]],pack,w−w[i−1],i−1)
return pack[(w,i)]
Время выполнения итогового решения составляет $O(nW)$, так как количество рекурсивных вызовов, не являющихся уточняющими запросами в ассоциативный массив, не превышает это число. Следовательно, это такое же время выполнения, как и у соответствующего итерационного алгоритма. На практике же итерационное решение, как правило, быстрее, потому что в нём нет рекурсивных издержек и оно использует более простые структуры данных. Например, массив вместо хеш-таблицы. Тем не менее с рассматриваемой задачей ситуация иная: при некоторых наборах данных, рекурсивная версия быстрее итерационной. К примеру, если мы умножим все весовые значения на $10$, то время выполнения итерационного алгоритма также умножится на $10$, в то время как время выполнения рекурсивного останется таким же. В целом, если необходимо решить все возможные подзадачи, итерационный вариант обычно быстрее.